目次
- 13.1. MySQLストレージエンジンアーキテクチャの概要
- 13.2. サポートされたストレージエンジン
- 13.3. ストレージエンジンの設定
- 13.4.
MyISAMストレージエンジン - 13.5.
InnoDBストレージ エンジン - 13.5.1.
InnoDB概要 - 13.5.2.
InnoDB連絡先情報 - 13.5.3.
InnoDB設定 - 13.5.4.
InnoDB起動オプションとシステム変数 - 13.5.5.
InnoDBテーブルスペースを作成する - 13.5.6.
InnoDBテーブルの作成と利用 - 13.5.7.
InnoDBデータとログ ファイルの追加と削除 - 13.5.8.
InnoDBデータベースのバックアップと復旧 - 13.5.9.
InnoDBデータベースを別のマシンに移動する - 13.5.10.
InnoDBトランザクション モデルとロック - 13.5.11.
InnoDBパフォーマンス チューニング ヒント - 13.5.12. マルチバージョンの実装
- 13.5.13.
InnoDBテーブルとインデックス構造 - 13.5.14.
InnoDBファイル領域の管理とディスク I/O - 13.5.15.
InnoDBエラー処理 - 13.5.16.
InnoDBテーブル上の制約 - 13.5.17.
InnoDBトラブルシューティング
- 13.5.1.
- 13.6.
MERGEストレージエンジン - 13.7.
MEMORY(HEAP) ストレージエンジン - 13.8.
EXAMPLEストレージエンジン - 13.9.
FEDERATEDストレージエンジン - 13.10.
ARCHIVEストレージエンジン - 13.11.
CSVストレージエンジン - 13.12.
BLACKHOLEストレージエンジン
MySQLは、異なるテーブルタイプのハンドラとして機能するいくつかのストレージエンジンをサポートします。MySQLストレージエンジンは、トランザクションセーフなテーブルを扱うものと、トランザクションセーフではないテーブルを扱うものの両方を含んでいます。
MySQL 5.1で MySQL ABは、動作中のMySQLサーバにストレージエンジンをロードしたりアンロードしたりできる、新しいプラガブルなストレージエンジンアーキテクチャを導入しました。
この章では、章?14. MySQL Clusterで紹介されているNDB
Cluster以外のMySQLストレージエンジンについて説明します。
プラガブルなストレージエンジンアーキテクチャについても説明しています。
(項13.1. 「MySQLストレージエンジンアーキテクチャの概要」を参照してください。)
MySQL ストレージエンジンについてのよくある質問に対する答えに関しては、項A.2. 「MySQL 5.1 FAQ ? Storage Engines」を参照してください。
MySQLのプラグ可能ストレージエンジンアーキテクチャは、特殊なアプリケーションコーディングを必要とせずに、データベースのプロが専門のストレージエンジンを選択する事を可能にします。 MySQLサーバアーキテクチャは、一貫した簡単なアプリケーションモデルとAPIを供給する事によって、アプリケーションプログラマとDBAを、ストレージレベルでの下位レベルの詳細な実装から切り離します。それにより、別々のストレージエンジン間で別々の機能があったとしても、アプリケーションはそれらの違いから守られるのです。
MySQLプラガブルストレージエンジンアーキテクチャは 図?13.1. 「プラガブルストレージエンジンを利用したMySQLアーキテクチャ」で紹介しています。
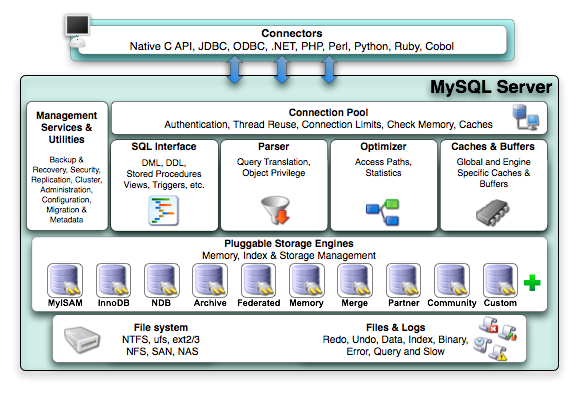
プラガブルストレージエンジンアーキテクチャは、全てのストレージエンジンに横断的に共通する標準的な管理とサポートサービスのセットを提供します。ストレージエンジン自体は、物理的サーバレベルで管理されている基礎データに直接働きかけるデータベースサーバのコンポネントです。
この効果的なモジュール式のアーキテクチャは、特殊なアプリケーションニーズ ? データウェアハウス、トランザクションプロセス、またはハイアベイラビリティなど? をターゲットとする人達に甚大な利益をもたらします。
アプリケーションプログラマとDBAは、ストレージエンジンの上位にある接続APIとサービスレイヤを通してMySQLデータベースと対話します。もしアプリケーションの変更が、下位のストレージエンジンの変更を必要とするような要求を引き起こしたり、新しい要求に対応するために複数のストレージエンジンが追加されたりしても、コーディングやプロセスの変更は特に必要ありません。MySQLサーバアーキテクチャは、ストレージエンジン全体に適応する一貫した使いやすいAPIによって、ストレージエンジンの複雑さからアプリケーションを守ります。
MySQLプラガブルストレージエンジンは、特別なアプリケーションニーズをターゲットとする特徴集合を有効にし、実行するだけでなく、実際のデータ入出力操作に責任を持つMySQLデータベースサーバの中のコンポネントです。特殊なストレージエンジンを利用する事の最大の利点は、特定のアプリケーションに必要な特徴だけが供給されるという事です。その結果、最終的にデータベースはより効果的で高性能になり、システムオーバーヘッドが少なくなります。業界標準ベンチマークの独自仕様モノリシック構造に適応し、さらに先を進んでいる事が、MySQLが常に高性能として知られている理由の1つです。
技術的観点から見て、ストレージエンジンの中にある固有サポート構造基盤コンポネントにはどのような物があるでしょう? 重要な特徴の区別には次のような物があります。
並行処理 ? いくつかのアプリケーションは他の物と比べて、より粒度の細かいロックを必要とします。 (行レベルロックのような物) 適切なロック方法を選択する事によりオーバーヘッドを減らす事ができ、その為全体的な性能も向上します。この分野はまた、マルチバージョン並行処理制御や「スナップショット」 読み込みのような機能もサポートします。
トランザクションサポート ? 全てのアプリケーションがトランザクションを必要とするわけではありませんが、必要とするアプリケーションに対しては、ACIDコンプライアンスのような明確な条件があります。
参照整合性 ? サーバーを持つ事によって、DDLに定義された外部キーを通してリレーショナルデータベース参照整合性が強調されます。
物理記憶 ? これは、ディスク装置にデータを記憶する為に利用されるフォーマットだけでなく、 テーブルとインデックス全体のページサイズを含んでいます。
インデックスサポート ? 異なるアプリケーションシナリオは異なるインデックスストラテジーの恩恵を受ける傾向があります。通常各ストレージエンジンは専用のインデックス方法を持ちますが、いくつかの方法は(Bツリーインデックス等)ほとんど全てのエンジンに共通しています。
メモリキャッシュ ? 異なるアプリケーションは、いくつかのメモリキャッシュストラテジに対して他の物より反応がよいです。その為、いくつかのメモリキャッシュが全てのストレージエンジン(ユーザ接続やMySQLの高速クエリキャッシュに利用される物など)に共通であるとしても、他の物は特定のストレージエンジンが稼動する時だけ一意に定義されます。
パフォーマンスエイド ? これはパネル操作の為の複数の入出力スレッド、スレッド並行処理、データベースチェックポイント、大量挿入操作等を含みます。
その他のターゲット特性 ? これは、地球空間的操作へのサポート、特定データのマニピュレーション操作への安全保障制限、そしてその他の類似特性などを含みます。
プラガブルなストレージエンジン構造基盤コンポネントのセットはそれぞれ、特定のアプリケーションに選りすぐった利益をもたらすようにデザインされています。反対に、コンポネント特性を無効にすると、不必要なオーバーヘッドを削減する事ができます。特定のアプリケーションの要求事項を理解し、適切なMySQLストレージエンジンを選択する事が、システム全体の効率と性能に劇的な衝撃を与えるのは明らかです。
MySQL 5.1では、MySQL ABが稼動中のMySQLサーバにストレージエンジンをロードしたり、そこからアンロードしたりできる、新しいプラガブルなストレージエンジンアーキテクチャを紹介しました。
ストレージエンジンを使用する前に、ストレージエンジンプラグイン共用ライブラリを INSTALL
PLUGIN
ステートメントを利用してMySQLにロードしなければいけません。例えば、EXAMPLE
エンジンプラグインが ha_example
と名づけられ、共有ライブラリが
ha_example.soと名づけられると、次のステートメントを利用してロードする事になります。
INSTALL PLUGIN ha_example SONAME 'ha_example.so';
共有ライブラリはMySQLサーバプラグインディレクトリの中に無ければいけません。その場所はplugin_dirシステム変数によって指示されます。
ストレージエンジンをアンプラグするには、UNINSTALL
PLUGIN ステートメントを利用します。
UNINSTALL PLUGIN ha_example;
もし、テーブルに必要なストレージエンジンをアンプラグすると、それらのテーブルはアクセス不可になりますが、ディスク上には存在し続けます。 (アクセス可能な場所)ストレージエンジンをアンプラグする前に、それらを利用しているテーブルが無い事を確認してください。
MySQL 5.1は次のストレージエンジンをサポートします。
MyISAM?デフォルトのMySQLストレージエンジンと、ウェブ、データウェアハウス、そしてその他のアプリケーション環境で一番利用されるストレージエンジンです。MyISAMは全てのMySQLコンフィギュレーションの中でサポートされています。そして、MySQLに他のストレージエンジンを設定しない限り、これがデフォルトとして利用されます。InnoDB? トランザクションプロセスアプリケーションに利用され、ACIDトランザクションサポートや外部キーなどを含む、複数の特徴をサポートします。InnoDBは全てのMySQL 5.1 バイナリディストリビューションの中にデフォルトとして含まれています。ソースディストリビューションの中では、好きなようにMySQLを設定する事によって、エンジンを有効にも無効にもできます。Memory? 参照事項や迅速なデータ検索を必要とする環境で、きわめて高速なアクセスで全てのデータをRAMの中に格納します。このエンジンは以前はHEAPエンジンとして知られていました。Merge? MySQL DBAや開発者が、一連の同一MyISAMテーブルを論理的にグループ化し、それらを1つのオブジェクトとして参照付ける事を可能にします。 VLDB データウェアハウスと同じで、VLDBに効果的です。Archive? サイズが大きいほとんど参照されない履歴、アーカイブ、セキュリティ監査情報を格納したり、検索する為の完璧な解決法を提供します。Federated? いくつもの物理的サーバーから、別々のMySQLサーバーをリンクさせて1つの論理データベースを作成する能力を提供します。 分散、またはデータマート環境に大変効果的です。NDB? 高い検索機能と、できるだけ長い稼働時間を必要とするアプリケーションにぴったりな、クラスタ化されたデータベースエンジンです。CSV? ストレージエンジンはコンマ区切りの値を使ったフォーマットでデータをテキストファイルに保存します。CSV エンジンは、 CSVフォーマットにインポート・エクスポートする事ができる他のソフトやアプリケーション間でデータを簡単に交換する為に利用する事ができます。Blackhole? ブラックホールストレージエンジンはデータの受け入れはしますが、格納はせず、検索しても結果は得られません。 この機能性は、データが自動的に複製される分散型のデータベースデザインの中で利用できますが,局所的に格納はされません。Example? このストレージエンジンは 「スタブ」 エンジンで実装されており、何の機能も持ちません。このエンジンを利用してテーブルを作成できますが、データの格納も検索もできません。このエンジンの目的は、MySQL ソースコードの中で新しいストレージエンジンを作成する方法を説明する為の、見本の役割を果たす事です。それ自体は、ソフトウェア開発者向のものです。
この章では、章?14. MySQL Clusterで紹介されているNDB
Cluster以外のMySQLストレージエンジンについて説明します。
サーバやスキーマ全体に同じストレージエンジンを利用しなければいけないという制限はないという事を覚えておいて下さい。スキーマの中のそれぞれのテーブルに違うストレージエンジンを利用する事ができます。
MySQLから提供される様々なストレージエンジンは異なるユースケースを想定してデザインされています。 プラグ可能ストレージアーキテクチャを効果的に利用する為には、様々なストレージエンジンの利点と欠点を知っておく事が役立ちます。次のテーブルは、MySQLが提供するいくつかのストレージエンジンの概要を表しています。
| 特徴 | MyISAM | メモリ | InnoDB | アーカイブ | NDB |
| ストレージリミット | 256TB | Yes | 64TB | No | 384EB[4] |
| トランザクション | No | No | Yes | No | Yes |
| ロック精度 | テーブル | テーブル | 行 | 行 | 行 |
| MVCC (スナップショット読み込み) | No | No | Yes | Yes | No |
| 地球空間サポート | Yes | No | Yes[1] | Yes[1] | Yes[1] |
| Bツリーインデックス | Yes | Yes | Yes | No | Yes |
| ハッシュインデックス | No | Yes | No | No | Yes |
| 前文検索インデックス | Yes | No | No | No | No |
| クラスタ化されたインデックス | No | No | Yes | No | No |
| データキャッシュ | No | N/A | Yes | No | Yes |
| インデックスキャッシュ | Yes | N/A | Yes | No | Yes |
| 圧縮データ | Yes | No | No | Yes | No |
| 暗号化されたデータ[2] | Yes | Yes | Yes | Yes | Yes |
| クラスタデータベースサポート | No | No | No | No | Yes |
| レプリケーションサポート[3] | Yes | Yes | Yes | Yes | Yes |
| 外字サポート | No | No | Yes | No | No |
| バックアップ / ポイントインタイムリカバリ[3] | Yes | Yes | Yes | Yes | Yes |
| クエリキャッシュサポート | Yes | Yes | Yes | Yes | Yes |
| データディレクトリの更新統計 | Yes | Yes | Yes | Yes | Yes |
[1] ストレージエンジンは空間データタイプはサポートしますが、それらをインデックスはしません。
[2] ストレージエンジンの中よりも、サーバーの中で実行されます。 (暗号化機能を利用)
[3] ストレージエンジンの中よりも、サーバーの中で実行されます。
[4] EB = exabyte (1024 * 1024 terabyte)
トランザクションセーフテーブル(TSTs)は、非トランザクションセーフテーブル(NTSTs)よりも利点がいくつかあります。
より安全です。もしMySQLがクラッシュしたり、ハードウェアに問題がおきても、自動修復機能かバックアップとトランザクションログでデータを取り戻す事ができます。
COMMITステートメントを利用して、いくつものステートメントを組み合わせたり、同時に受け入れたりする事ができます。 (自動コミットが無効の時)変更を無視する為に
ROLLBACKを実行する事ができます。 (自動コミットが無効の時)もし更新に失敗したら、全ての変更は元に戻ります。(非トランザクションセーフテーブルを利用すると、全ての変更は永久的です。)
トランザクションセーフストレージエンジンは、読み込みと更新の並行作業が多いテーブルに、より良い並行処理を提供する事ができます。
トランザクションセーフと、非トランザクションセーフテーブルの両方を同じステートメントの中で組み合わせて、両方の利点を利用する事ができます。しかし、MySQLがいくつかのトランザクションセーフストレージエンジンをサポートしていても、良い結果を出す為に、自動コミットが無効の時は異なるストレージエンジンを1つのトランザクションの中に混在させない方がよいです。
例えば、もしこれをしてしまうと、非トランザクションセーフテーブルへの変更が行われてしまい、ロールバックできなくなってしまいます。複数のストレージエンジンをミックスして利用する時に起こるこのような問題や、これ以外の問題に関しての情報については、項12.4.1. 「START
TRANSACTION、COMMIT、そして
ROLLBACK 構文」を参照してください。
非トランザクションセーフテーブルには、トランザクションオーバーヘッドが無い為に起こるいくつかの利点があります。
より速い
より少ないディスク領域
更新時に必要とするメモリがより少ない
その他のストレージエンジンは、カスタムストレージエンジンインターフェースを利用した第三者やコミュニティメンバから入手する事ができるでしょう。
MySQLフォージストレージエンジン ページにある、第三者ストレージエンジンのリストに、更なる情報が紹介されています。
注意
第三者エンジンはMySQLにサポートされていません。これらのエンジンに関しての更なる情報、文書、インストールガイド、バグレポート、または支援等が必要であれば、エンジンディレクトリの開発者に連絡してください。
利用可能な第三者エンジンは次の物を含んでいます。更なる情報については、フォージリンクを参照してください。
PrimeBase XT (PBXT) ? PBXTはモデム、ウェブベース、高い同時並行性を持つ環境の為にデザインされています。
RitmarkFS ? RitmarkFSを利用すると、SQLクエリを利用してファイルシステムにアクセスしたり、複製したりできます。 RitmarkFSはファイルシステムの複製と、ディレクトリ変更のトラッキングもサポートします。
分散データエンジン ? 分散データエンジンは、作業負荷統計による分散データにストレージエンジンを提供するという作業専用の、オープンソースプロジェクトです。
mdbtools ? Microsoft Access
.mdbデータベースファイルに読み取り専用アクセスを許可するプラグ可能なストレージエンジンです。solidDB for MySQL ? MySQLのsolidDBストレージエンジンは、オープンソースであり、MySQLサーバーのトランザクションストレージエンジンです。 これは、強固なトランザクションデータベースを必要とする基幹インプリメンテーションの為にデザインされています。MySQLのsolidDBストレージエンジンは、予測される全てのトランザクション分離レベル、低レベルロック、そしてノンブロッキングの読み込みと書き込みができるマルチバージョン並行処理コントロール(MVCC)を持つフルACIDコンプライアンスをサポートする、マルチスレッドストレージエンジンです。
プラガブルなストレージエンジンアーキテクチャと一緒に利用できるカスタマーストレージエンジンの開発については、MySQL内部マニュアルの中にある Writing a Custom Storage Engine on MySQL Forge を参照してください。
新しいテーブルを作成する時、ENGINE
テーブルオプションを CREATE TABLE
ステートメントに加える事によって、どのストレージエンジンを利用するかを指定できます。
CREATE TABLE t (i INT) ENGINE = INNODB;
ENGINE か TYPE
オプションを省略すると、デフォルトのストレージエンジンが利用されます。通常、これは
MyISAMですが、--default-storage-engine
か --default-table-type
サーバー始動オプションを利用、またはmy.cnf
構造ファイルの中の
default-storage-engine か
default-table-type オプション
を設定する事で変更できます。
現在のセッションの途中で
storage_engine
変数を設定する事によって、利用するデフォルトストレージエンジンを設定する事ができます。
SET storage_engine=MYISAM;
MySQLコンフィギュレーションウィザードを利用してMySQLがWindowsにインストールされた時は、MyISAMの代わりに
InnoDB
ストレージエンジンをデフォルトとして選択する事ができます。詳しくは項2.3.4.6. 「データベースの使用ダイアログ」を参照してください。
テーブルを別のストレージエンジンに変換するには、新しいエンジンを指示するALTER
TABLE
ステートメントを利用してください。
ALTER TABLE t ENGINE = MYISAM;
項12.1.8. 「CREATE TABLE 構文」と項12.1.2. 「ALTER TABLE 構文」を参照して下さい。
もし、編集されていないストレージエンジンや、編集はされていても無効になっているストレージエンジンを利用しようとすると、MySQLは代わりにデフォルトのストレージエンジンを利用しててテーブルを作成します。通常その時利用されるのはMyISAMです。この機能は、別々のストレージエンジンをサポートするMySQLサーバー間でテーブルをコピーしたい時に便利です。(例えば、複製を設定する時、マスターサーバは安全の為トランザクションストレージエンジンをサポートするでしょう。しかし、スレーブサーバはスピードの為に、非トランザクションストレージエンジンだけを利用します。)
新しいMySQLユーザにとっては、利用不可デフォルトストレージエンジンの自動置換は複雑かもしれません。ストレージエンジンが自動的に変更された時は必ず、警告メッセージが表示されます。
テーブルとカラムの定義を維持する為に、MySQLは毎回新しいテーブルの為に
.frm
を作成します。ストレージエンジンによっては、テーブルのインデックスとデータは複数の別のファイルに格納されるでしょう。サーバーがストレージエンジンレベルの上位に
.frm
ファイルを作成します。個々のストレージエンジンは、それらが管理するテーブルが必要とする追加ファイルも作成します。もしテーブル名が特別な文字を含んでいる場合、そのテーブルファイルの名前は項8.2.3. 「ファイル名への識別子のマッピング」に表されているようにそれらの文字が暗号化された形を含んだ物になります。
データベースは異なるタイプのテーブルを含む事があります。これは、テーブルが同じストレージエンジンで作成されなくても良い事を表しています。
MyISAM
はデフォルトストレージエンジンです。古い
ISAM
コードに基づいていますが、便利な拡張子を多く持っています。(MySQL
5.1 は ISAMをサポート
しない
事を覚えておいてください。)
各 MyISAM
テーブルはディスク上に3つのファイルとして保管されます。そのファイル名はテーブル名で始まり、ファイルタイプを指示する拡張子が付きます。.frm
ファイルはテーブルフォーマットを格納します。データファイルには
.MYD (MYData)
拡張子が付きます。インデックスファイルには
.MYI (MYIndex)
拡張子が付きます。
MyISAMテーブルが必要だという事を明確に指示したい場合は、ENGINE
テーブルオプションを指定します。
CREATE TABLE t (i INT) ENGINE = MYISAM;
通常、MyISAM
ストレージエンジンを指示するのにENGINEを使用する必要はありません。変更されない限り、MyISAM
がデフォルトエンジンです。デフォルトが変更されている可能性がある場合に
MyISAM
を確実に利用する為には、ENGINEオプションを確実に包括してください。
mysqlcheck クライアントか
myisamchk
ユーティリティでMyISAM
テーブルをチェックしたり、修正したりする事ができます。容量を節約する為にmyisampackを使って
MyISAM
テーブルを圧縮できます。項7.11. 「mysqlcheck ? テーブル メンテナンスと修復プログラム」、項4.9.4.1. 「myisamchk でクラッシュ リカバリ」、項7.6. 「myisampack ? 圧縮された、読み取り専用MyISAM テーブルを作成する。」を参照して下さい。
MyISAM
テーブルには次のような特徴があります。
全てのデータ値は最初は下位バイトで格納されます。その為、データマシーンとOSは独立します。バイナリポータビリティに対する唯一の条件は、マシンが2個の補数符号付の整数とIEEE浮動小数点フォーマットを使用するという事だけです。これらの条件は主流マシンの間で広く利用されています。バイナリ互換性は、固有のプロセッサを持つ事がある内蔵システムには適合しない可能性があります。
データを最初に下位バイトで格納する事に関して、スピードに関する重大なペナルティはありません。テーブル行内のバイトは通常非同盟であり、非同盟バイトを順番に読み込むのは、逆の順番で読み込むよりも少し手間がかかります。また、カラム値をフェッチするサーバー内のコードは、他のコードに比べるとタイムクリティカルではありません。
全ての数値キー値は、よりよいインデックス圧縮の為に、上位バイトの物から先に格納されます。
大きいファイル (最高63-bitファイル) は、専用のファイルシステムとOSによってサポートされています。
MyISAMテーブルには232 (~4.295E+09) 行の制限があります。MySQLを--with-big-tablesオプションで作成すると、行の制限を (232)2 (1.844E+19) 行に増加させる事ができます。詳しくは項2.9.2. 「典型的な configure オプション」を参照してください。MySQL 5.0.4バージョンより、全ての標準バイナリはこのオプションで作成されます。1つの
MyISAMテーブルのインデックス数は最高64です。これは再コンパイルする事によって変更できます。MySQL 5.1.4から、1つのMyISAMテーブルに許可されているインデックス数の最高値がNの場合、--with-max-indexes=オプションを使ってconfigureを呼び出す事によって体型を設定できるようになりました。NNは128以下でなければいけません。MySQL 5.1.4以前のバージョンではソースを変える必要があります。各インデックスのカラム最高数は16です。
最高キー長さは1000バイトです。これも、ソースを変えたり、再コンパイルする事によって変える事ができます。 キー長さが250バイト以上の場合は、デフォルトの1024バイトよりも大きいキーブロックサイズが使用されます。
ソートされた順番で行が挿入された時(
AUTO_INCREMENTカラムを使用している時と同様に)、高ノードが1つのキーだけを含むように、インデックスツリーが分割されます。 このおかげでインデックスツリーのスペース利用は向上します。1つのテーブルに対する1つの
AUTO_INCREMENTカラムの内部操作がサポートされます。MyISAMはINSERTとUPDATE操作のカラムを自動的に更新します。そのおかげでAUTO_INCREMENTカラムは速くなります。 (最低10%)シーケンスの最上部の値が削除された後に再利用される事はありません。(AUTO_INCREMENTが複数カラムインデックスの最後のカラムとして定義された場合は、シーケンスの最上部から削除された値が再利用される事があります。)AUTO_INCREMENT値はALTER TABLEや myisamchkでリセットできます。動的サイズの行は、削除作業をアップデートと挿入でミックスした時には断片化される事が少なくなります。隣のブロックが削除された時に、隣接している削除されたブロックを自動的に一体化したり、ブロックを拡張したりする事でこれを行います。
もしテーブルのデータファイルの間に開いているブロックがなければ、他のスレッドが読み込みをしているのと同時に新しい行を
INSERTする事ができます。(これらは並列挿入として知られています。)行を削除する事や、それ自体の現在の内容よりも多くのデータを持つ動的長さの行をアップデートする事によって、フリーブロックが生じます。全てのフリーブロックが使用された(記入された)時、その後の挿入は再度並列になります。詳しくは項6.3.3. 「同時挿入」を参照してください。スピードを上げるために
DATA DIRECTORYとINDEX DIRECTORYテーブルオプションへのCREATE TABLEを使って、データファイルとインデックスファイルを別々のディレクトリに入れる事ができます。詳しくは項12.1.8. 「CREATE TABLE構文」を参照してください。BLOBとTEXTカラムはインデックスする事ができます。NULL値がインデックスカラムの中で許可されています。1つのキーに対して0?1 バイト使われます。それぞれのキャラクタカラムは異なるキャラクタセットを持つ事ができます。詳しくは章?9. キャラクタセットサポートを参照してください。
MyISAMインデックスファイルの中に、テーブルが正しく閉じられたかどうかを表すフラグがあります。もしmysqld が--myisam-recoverオプションで開かれるとMyISAMテーブルは自動的にチェックされて、もし正しく閉じられてなかった時には修正されます。myisamchk を
--update-stateオプションで実行すると、チェックしたテーブルにマークをつけます。myisamchk --fast はこのマークがないテーブルだけをチェックします。myisamchk --analyze はキー全体に対してするのと同様に、キーの一部分に統計データを格納します。
myisampack は
BLOBとVARCHARカラムを圧縮する事ができます。
MyISAM
は次のような特徴をサポートします。
本物の
VARCHARタイプへのサポート;VARCHARカラムは1バイトか2バイトで格納された長さから始まります。VARCHARカラムを持つテーブルの行の長さは固定、または動的になり得ます。1つのテーブル内の
VARCHARとCHARカラム長さの合計は、最高で 64KBになるでしょう。任意長さ
UNIQUE制約。
追加情報
MyISAMストレージエンジンを専門に扱うフォーラムがあります。http://forums.mysql.com/list.php?21。
MyISAM
テーブルの性能を変える為に次の
mysqld
オプションを使う事ができます。追加情報については
項4.2.2. 「コマンド オプション」を参照してください。
次のシステム変数はMyISAM
テーブルの性能に影響を与えます。追加情報については
項4.2.3. 「システム変数」を参照してください。
bulk_insert_buffer_size大量挿入最適化で使用されるツリーキャッシュのサイズ。注:これはそれぞれのスレッドのリミットです!
myisam_max_sort_file_sizeMyISAMインデックスを再作成している最中にMySQLが使用を許されているテンポラリファイルの最大サイズ (REPAIR TABLE、ALTER TABLE、 またはLOAD DATA INFILEの最中)。もしファイルサイズがこの値よりも大きければ、代わりにキーキャッシュを使用してインデックスが作成されますが、この方法のほうが遅くなります。値はバイトで表示されます。myisam_sort_buffer_sizeテーブルをリカバする時に使用されるバッファのサイズを設定します。
もし --myisam-recover
オプションを利用してmysqldをスタートさせれば、自動修復が作動します。この場合、サーバーが
MyISAM
テーブルを開いた時に、テーブルにクラッシュのマークが付いているかどうかや、テーブルのオープンカウント変数が0でないかどうか、そして外部ロックが使用不可能な状態でサーバーを作動させているかどうかを確認します。もしこのような条件が整っていると、次のような事が起こります。
サーバーがテーブルのエラーをチェックします。
もしサーバーがエラーを発見すると、高速テーブル修復を試みます。(データファイルの保存はしますが、再作成はしません。)
データファイル中のエラーのせいで修復が失敗したら、(例えば重複キーエラー)、サーバーは今度はデータファイルを再作成してもう一度修復を行います。
もし修復がまた失敗したら、サーバーは古い修復オプションの方法でもう一度修復を試みます (ソートせず一行ずつ書く)。この方法であればどんなタイプのエラーも修復し、ディスクのスペースも少しで済みます。
MySQL Enterprise
もし --myisam-recover
オプションがセットされていなければ、MySQL
Network Monitoring and Advisory
Serviceの加入者は通知を受け取ります。追加情報については
http://www-jp.mysql.com/products/enterprise/advisors.htmlを参照してください。
もし以前に完成されたステートメントから全ての行を回復できず、--myisam-recover
オプション値の中のFORCEを指定しなければ、
自動修復はエラーログにエラーメッセージを残して異常終了します。
Error: Couldn't repair table: test.g00pages
もし
FORCEを指定すると、代わりにこのような警告が書かれます。
Warning: Found 344 of 354 rows when repairing ./test/g00pages
もし自動修復値がBACKUPを含んでいる時、修復プロセスはtbl_name-datetime.BAK
MyISAM
テーブルはBツリーインデックスを使用します。インデックスファイルのサイズは、全てのキーを大体
(key_length+4)/0.67のように計算し、それらを合計して大まかに算出する事ができます。fこれは、全てのキーがソートされた順番に挿入され、かつキーが全く圧縮されない時を想定した最悪のケースです。
文字列インデックスでは空白が圧縮されます。もしインデックスの最初の部分が文字列であれば、プリフィックスもまた圧縮されます。文字列カラムに含まれる後続の空白が長い場合、またはそのカラムが
VARCHARカラムであるためにその長さがフルに使用されることがない場合は、空白の圧縮によってインデックスファイルが上記の数値よりも小さくなります。プレフィックス圧縮は文字列で始まるキーに使用されます。同一のプリフィックスを持つ文字列が多数存在する場合は、プリフィックスの圧縮が役立ちます。
MyISAMテーブルでは、テーブル作成時に
PACK_KEYS=1
を指定する事で、数値のプリフィックスを圧縮する事もできます。この機能は、数値が上位バイトから順に格納される場合に、同一のプリフィックスを持つ整数キーが多数ある時に役立ちます。
MyISAM
は3つの異なるストレージフォーマットをサポートします。そのうちの2つである静的、または動的フォーマットは、使用しているカラムタイプによって自動的に選択されます。3つめである圧縮フォーマットは、myisampack
ユーティリティーでしか作成する事ができません。
BLOB や TEXT
カラムを持たないテーブルに対して、CREATE
TABLEか ALTER
TABLEカラムを使用する時、ROW_FORMAT
テーブルオプションで、テーブルフォーマットをFIXED
か DYNAMICに強制する事ができます。
ALTER TABLEを使った
ROW_FORMAT=DEFAULT
を指定する事で、テーブルを復元する事ができます。
ROW_FORMATについての情報は項12.1.8. 「CREATE TABLE 構文」を参照してください。
静的フォーマットは MyISAM
テーブルのデフォルトです。これは、テーブルが可変長カラムを持たない時に使用されます。
(VARCHAR、 VARBINARY、
BLOB、また
TEXT)それぞれの行は固定バイト数を利用して格納されます。
3つの MyISAM
ストレージフォーマットの中で、静的フォーマットが一番シンプルで安全です。(一番破損しにくい)これはまた、データファイル中の行がディスク上で見つけられるという簡単さゆえ、オンディスクフォーマットの中でも一番早いです。インデックスの中で行数に基づいて行の位置を探すには、行数に行長をかけてください。また、テーブルをスキャンする時には、それぞれのディスクの読み込み操作を使って簡単に行の定数を読む事ができます。
もしMySQLサーバーが固定フォーマットのMyISAMファイルに書き込んでいる最中にコンピュータがクラッシュしたら、そのセキュリティが証明されます。この場合、myisamchk
はそれぞれの行がどこで始まりどこで終わるかを簡単に測定する事ができますので、部分的に書かれた物以外の全ての行を大概再生する事ができます。MyISAM
テーブルインデックスは、データ行に基づいていつでも再配列できるという事を覚えておいてください。
注意
固定長の行フォーマットはBLOB
か TEXT
カラムの無いテーブルでだけ使用する事ができます。明確な
ROW_FORMAT
条項を持つカラムを使ってテーブルを作成する事によって、エラーや警告は発生しません。フォーマットの仕様は無視されるのです。
静的フォーマットにはこれらの特徴があります。
CHARとVARCHARカラムは、タイプは変えられていませんが、特定のカラム幅にスペースが埋め込まれた物です。BINARYとVARBINARYカラムは幅が0x00バイトで埋め込まれています。とても速いです。
キャッシュが簡単です。
行が固定位置にあるので、クラッシュした後も修復が簡単です。
莫大な数の行を削除してしまい、フリーディスクスペースをOSに戻したい時以外は、再編成の必要はありません。これをするには、
OPTIMIZE TABLEか myisamchk -rを使用してください。ほとんどの場合、動的フォーマットテーブルよりもディスクの領域を必要とします。
もし MyISAM
テーブルが可変長カラムを含んでいる場合(VARCHAR、
VARBINARY、
BLOB、または
TEXT)、または
ROW_FORMAT=DYNAMIC
テーブルオプションで作成された場合は、動的ストレージフォーマットが使用されます。
動的フォーマットは、それぞれの行にその長さを示すヘッダーがあるので、静的フォーマットよりも少しだけ複雑です。更新の結果行が長くなった時には、フラグメント化する事ができます。(非連続単位での格納)
テーブルをデフラグメント化する為に
OPTIMIZE TABLE か myisamchk
-r
を使用する事ができます。頻繁にアクセスや変更がある固定長カラムが、可変長カラムも含むテーブルの中にあるなら、フラグメント化を防ぐ為に、可変長カラムを他のテーブルに移動するとよいでしょう。
動的フォーマットにはこれらの特徴があります。
長さが4以下の物以外の全ての文字列カラムは動的カラムです。
それぞれの行の先頭には、どのカラムが空文字列(文字列カラム)なのか、またはゼロ(数字カラム)なのかを示すビットマップが付いています。
NULL値を含むカラムは、これに含まれていない事を覚えておいてください。後続スペースの除去をした後に文字列カラムの長さがゼロになったり、数字カラムの値がゼロだったりすると、それらはビットマップの中でマークが付けられ、ディスク上には保存されません。空ではない文字列は、長さバイトに加えて文字列コンテンツとして保存されます。通常、固定長テーブルに比べると少量のディスク容量を必要とします。
それぞれの行は、必要とする容量のみを使用します。しかし、行が大きくなれば、要求されただけの単位に分割され、行のフラグメント化が行われます。例えば、行の長さを延長する情報を使って行を更新すると、その行はフラグメント化されます。このような場合は、性能を上げるために
OPTIMIZE TABLEか myisamchk -r を時々行う必要があるでしょう。テーブル統計を得る為には myisamchk -ei を利用してください。行がいくつもの単位にフラグメント化されていて、リンク(フラグメント)がなくなっているかもしれないので、静的フォーマットテーブルよりも、クラッシュ後の再配列は難しいです。
動的サイズの行の予想長さは次の表現を使って計算されます。
3 + (
number of columns+ 7) / 8 + (number of char columns) + (packed size of numeric columns) + (length of strings) + (number of NULL columns+ 7) / 8それぞれのリンクには6バイトのペナルティがあります。更新する事で行が拡大されると必ず動的行はリンクされます。新しいリンクはそれぞれ20バイトなので、次に行が拡大される時も同じリンクになるでしょう。そうでなければ別のリンクが作成されます。 myisamchk -edを利用してリンク数を確認する事ができます。
OPTIMIZE TABLEか myisamchk -rを使って全てのリンクを除去する事ができます。
圧縮ストレージフォーマットはmyisampack ツールによって生成される読み取り専用のフォーマットです。圧縮テーブルは myisamchkを使って解凍する事ができます。
圧縮テーブルには次のような特徴があります。
圧縮テーブルはごくわずかなディスク容量しか必要としません。そのおかげでディスクの使用を最小化する事ができるので、低速ディスク (CD-ROMなど)を利用する時に便利です。
それぞれの行が別々に圧縮されるので、アクセスオーバーヘッドがほとんどありません。行のヘッダーは、そのテーブルの中の一番大きな行に応じて、1から3バイトに固定されます。それぞれのカラムは違う方法で圧縮されます。それぞれのカラムは通常異なったハフマンツリーを持ちます。以下はいくつかの圧縮タイプの例です。
サフィックス空白の圧縮
プレフィックス空白の圧縮
値0の数値は1ビットで格納されます。
値の範囲が小さい整数カラムは、可能な限り小さな型を使って格納されます。例えば、
BIGINTカラム (8バイト)の全ての値が-128から127の範囲内にある場合は、このカラムをTINYINTカラム(1バイト)として格納する事ができます。カラムの可能値が少ない場合は、データの型を
ENUMに変換します。上記の圧縮を組み合わせて使用する事もできます。
固定長または可変長の行を処理する事ができます。
注:?
圧縮テーブルは読み取り専用なので、テーブルを更新したり、行を追加したりはできません。DDL
(データ定義言語)
操作は有効です。例えば、テーブルをドロップする為に
DROP
を利用したり、空にする為に
TRUNCATE
を利用する事もできます。
MySQL がデータの格納に使用するファイル形式は広範な検査を受けていますが、データベーステーブルの破損を招きかねない状況は常に存在します。 次にどのようにしてそれらが起きるのか、そしてどのように対処すればよいのかを紹介します。
MyISAM
は信頼性の高いテーブル形式ですが、(テーブルに対するすべての変更は
SQL
ステートメントから制御が戻る前に書き込まれます)それでも以下の状況が発生した場合はテーブルが破損するおそれがあります。
mysqld プロセスが書き込みの最中に強制終了された場合。
コンピューターが予期せずシャットダウンされた場合。 (例えばコンピューターの電源が切られた時。)
ハードウェアエラー
サーバー上でテーブルを修正中に外部プログラム (myisamchkなど) を利用した時。
MySQLまたは
MyISAMコードのソフトウェアバグ。
テーブルが破損すると通常次のような現象が見られます。
テーブルからデータを選択する時に次のようなエラーが表示されます。
Incorrect key file for table: '...'. Try to repair it
クエリがテーブルでレコードを検出できない、または不完全なデータを返します。
MyISAM
テーブルが破損していないかどうか CHECK
TABLE
ステートメントを利用して確認する事ができます。また、REPAIR
TABLEを利用して破損した
MyISAM
テーブルを修復する事ができます。また、mysqld
が稼動していない時はmyisamchk
コマンドを利用して確認や修復ができます。項12.5.2.3. 「CHECK TABLE 構文」、項12.5.2.6. 「REPAIR TABLE 構文」、項7.4. 「myisamchk ? MyISAM テーブル メンテナンス ユーティリティ」を参照して下さい。
もしテーブルが頻繁に破損する場合は、その原因を突き止める必要があります。最も重要なのは、サーバーのクラッシュによってテーブルが破損されたのかどうかを確認する事です。最近のエラーログの中の
restarted mysqld
メッセージを探せば簡単に検証する事ができます。もしそのようなメッセージがあれば、破損の原因はサーバーの破損によるものである可能性が高いでしょう。そうでなければ、破損は通常作業の最中に起きたという事になるでしょう。その場合はバグです。ですので、その破損のテストケースを作成してみる必要があります。項B.1.4.2. 「What to Do If MySQL Keeps Crashing」、Making a Test Case If You Experience Table Corruption
を参照して下さい。
MySQL Enterprise 問題が発生する前にそれを発見します。サーバーの状態についての専門家のアドバイスを受ける為に、MySQL ネットワークモニタリングとアドバイザーサービスを購読してください。追加情報については http://www-jp.mysql.com/products/enterprise/advisors.htmlを参照してください。
各 MyISAM インデックスファイル
(.MYI ファイル)には
テーブルが適切に閉じられているかをチェックする為のカウンタがあります。もし
CHECK TABLE か
myisamchkから次のような警告が表示されたら、このカウンタは同期されていない事を表します。
clients are using or haven't closed the table properly
この警告は、テーブルが破損されたという意味ではありませんが、少なくともテーブルを確認したほうがよいでしょう。
カウンターは次のように機能します。
MySQL でテーブルが最初に更新される時に、インデックスファイルのヘッダ内にあるカウンタが増加します。
その後の更新ではカウンタは変更されません。
(
FLUSH TABLES操作が行われた、またはテーブルキャッシュの中に場所が無い為 )テーブルの最後のインスタンスが閉じられると、それまでにテーブルが更新されていればカウンタが減少します。テーブルを修復するか、チェックして問題がなかった場合は、カウンタがゼロにリセットされます。
テーブルを検査する他のプロセスとの相互作用に伴う問題を回避する為、カウンタがゼロである場合は、テーブルを閉じる際にカウンタは減少しません。
つまり、カウンタがずれる可能性があるのは次のような場合です。
MyISAMテーブルがLOCK TABLESとFLUSH TABLESを発行せずにコピーされた。MySQL が更新されてから閉じられるまでの間にクラッシュした。(ただし、MySQL は各ステートメントで生じたすべての書き込みを次のステートメントまでに発行する為、テーブルが無事である可能性もあります)。
mysqldによって使用されていたのと同時にmyisamchk --recover か myisamchk --update-state によってテーブルが更新された。
別のサーバーによって使用されている最中に、複数の mysqld サーバーがテーブルを使用し、1つのサーバーが
REPAIR TABLEかCHECK TABLEを実行した。この場合、他のサーバーから警告を受けるかもしれないが、CHECK TABLEを使用してもよい。しかし、サーバーがデータファイルを新しい物と交換するとそれが別のサーバーに通知されないので、REPAIR TABLEは避ける必要がある。通常、複数サーバー間でデータディレクトリを共有するのはよくない事です。追加情報に関しては 項4.12. 「同じマシン上での複数 MySQL サーバの実行」を参照してください。
- 13.5.1.
InnoDB概要 - 13.5.2.
InnoDB連絡先情報 - 13.5.3.
InnoDB設定 - 13.5.4.
InnoDB起動オプションとシステム変数 - 13.5.5.
InnoDBテーブルスペースを作成する - 13.5.6.
InnoDBテーブルの作成と利用 - 13.5.7.
InnoDBデータとログ ファイルの追加と削除 - 13.5.8.
InnoDBデータベースのバックアップと復旧 - 13.5.9.
InnoDBデータベースを別のマシンに移動する - 13.5.10.
InnoDBトランザクション モデルとロック - 13.5.11.
InnoDBパフォーマンス チューニング ヒント - 13.5.12. マルチバージョンの実装
- 13.5.13.
InnoDBテーブルとインデックス構造 - 13.5.14.
InnoDBファイル領域の管理とディスク I/O - 13.5.15.
InnoDBエラー処理 - 13.5.16.
InnoDBテーブル上の制約 - 13.5.17.
InnoDBトラブルシューティング
InnoDB は MySQL
に、コミット、ロールバック、クラッシュ復旧機能を持つトランザクション
セーフ(ACID 適合)ストレージ
エンジンを提供します。InnoDB
は行レベルでのロックを行い、SELECT
ステートメント内で Oracle
スタイルの一貫した非ロック
リードを提供します。
これらの特徴により、複数ユーザによる並行処理とその性能が向上します。InnoDB
内では、行レベル
ロックは領域をほとんど利用しないので、ロックを向上させる必要はありません。InnoDB
は FOREIGN KEY
制約もまたサポートします。同じステートメント内で
InnoDB テーブルと別の MySQL
ストレージ
エンジンからのテーブルを混合する事ができます。
InnoDB
は大容量データ処理の最大性能の為に設計されました。その
CPU 性能に匹敵するディスク
ベースのリレーショナル データベース
エンジンは他にはないでしょう。
InnoDB ストレージ エンジンは、MySQL
サーバと完全に融和し、メイン
メモリ内にデータとインデックスをキャッシュする為の、それ自身のバッファ
プールを維持します。InnoDB
は、いくつかのファイル(または未加工ディスク
パーティション)で構成されるであろうテーブル領域内にそのテーブルとインデックスを格納します。これは例えば、各テーブルが別々のファイルを利用して格納される
MyISAM
テーブルとは異なります。InnoDB
テーブルは、ファイル サイズが 2GB
に制限されている OS
上で、どんなサイズにもなり得ます。
InnoDB はバイナリ
ディストリビューションの中にデフォルトとして含まれています。Windows
Essentials
インストーラによって、InnoDB は
Windows 上で MySQL のデフォルト ストレージ
エンジンになります。
InnoDB
は高性能が求められる数々の大型データベース
サイトにて、製造に利用されます。有名なインターネット
ニュース サイト Slashdot.org は InnoDB
で起動しています。Mytrix, Inc. は
InnoDB 内に1TB
以上のデータを格納し、別のサイトは
InnoDB 内で一秒に800
の挿入/更新の平均負荷を扱っています。
InnoDB は、MySQL と同じ GNU GPL
ライセンス
バージョン2(1991年6月)によって発行されています。MySQL
のライセンスについての更なる情報に関しては、http://www.mysql.com/company/legal/licensing/
を参照してください。
追加情報
InnoDBストレージ エンジンを専門に扱うフォーラムがあります。 http://forums.mysql.com/list.php?22
Innobase Oy の連絡先情報、InnoDB
エンジンの作成元:
Web site: http://www.innodb.com/
Email: <sales@innodb.com>
Phone: +358-9-6969 3250 (office)
+358-40-5617367 (mobile)
Innobase Oy Inc.
World Trade Center Helsinki
Aleksanterinkatu 17
P.O.Box 800
00101 Helsinki
Finland
InnoDB ストレージ
エンジンはデフォルトにて有効になっています。もし
InnoDB
テーブルを利用したくなければ、お使いの MySQL
オプション ファイルに skip-innodb
オプションを追加する事ができます。
注意:InnoDB
は MySQL
に、コミット、ロールバック、クラッシュ復旧機能を持つトランザクション
セーフ(ACID 適合)ストレージ
エンジンを提供します。しかし、もし基礎となる
OS
やハードウェアが広告どおりに機能しなければ、それを行う事はできません。多くの
OS やディスク サブ
システムが、性能を向上させる為に書き込み操作を遅らせたり再オーダしたりするでしょう。いくつかの
OS
上で、ファイルの全ての未書き込みデータがフラッシュされるまで待つ必要があるそのシステムコール、?
fsync() ?
は、実際にデータが安定したストレージにフラッシュされる前に返されます。この為、OS
のクラッシュや停電によって最近コミットされたデータが破損したり、さらに最悪の場合、書き込み操作が再オーダされた為にデータベースが破損する事もありますもしデータの整合性が重要であるなら、製造で何かを利用する前に
「pull-the-plug」 テストを行うべきです。Mac
OS X 10.3
以降のバージョンでは、InnoDB
は特別な fcntl() ファイル
フラッシュ法を利用します。Linux
下では、ライト バック
キャッシュを無効にする
事をお勧めします。
ATAPI ハードディスク上では、hdparm -W0
/dev/hda のようなコマンドがライト バック
キャッシュを無効にする働きをします。いくつかのドライブやディスク
コントローラでは、ライト バック
キャッシュを無効にできない可能性が有るので注意してください。
InnoDB ストレージ
エンジンによって管理されている2つの重要なディスク
ベース リソースは、そのテーブルスペース
データ ファイルとログ ファイルです。
注意:もし
InnoDB
設定オプションを全く指定しなければ、MySQL は
MySQL データ
ディレクトリ内に、ibdata1
という名前の 10MB の自動延長データ
ファイルと、ib_logfile0 と
ib_logfile1 という名前の 5MB のログ
ファイルを作成します。高性能を得るには、次の例にあるように
InnoDB
パラメータを明示的に提供する必要があります。当然ながら、お使いのハードウェアとその要求に合うように、設定を編集する必要があります。
MySQL Enterprise ご自分専用の環境に適応する設定に関するアドバイスの為に、MySQL ネットワーク モニタリングとアドバイス サービスの購読をお勧めします。追加情報については http://www-jp.mysql.com/products/enterprise/advisors.html を参照してください。
ここに表されている例は代表的な物です。InnoDB
に関連した設定パラメータに関する追加情報は、項13.5.4. 「InnoDB 起動オプションとシステム変数」を参照してください。
InnoDB テーブルスペース
ファイルを設定する為には、my.cnf
オプション ファイルの [mysqld]
セクション内の innodb_data_file_path
オプションを利用してください。Windows
上では、代わりに my.ini
を利用する事ができます。innodb_data_file_path
の値は、1つまたは複数のデータ
ファイル仕様のリストでなければいけません。複数のデータ
ファイルに名前を付けたら、セミコロン文字(‘;’)でそれらを区切ってください:
innodb_data_file_path=datafile_spec1[;datafile_spec2]...
例えば、デフォルトと同じ特徴を持つテーブル スペースを明示的に作成する設定は、次のようになります:
[mysqld] innodb_data_file_path=ibdata1:10M:autoextend
この設定は、ibdata1
と名づけられた自動延長の単一10MB データ
ファイルを構成します。そのファイルの場所は指定されない為、InnoDB
がデフォルトでそれを MySQL データ
ディレクトリ内に作成します。
MB か GB の単位を指定する為に、M
か G
のサフィックス文字を利用してサイズが指定されます。
データ ディレクトリ内で、ibdata1
と名づけられた固定サイズ50MB のデータ
ファイルと、ibdata2
と名づけられた50MBの自動拡大ファイルを含むテーブル
スペースは、次のように設定されます:
[mysqld] innodb_data_file_path=ibdata1:50M;ibdata2:50M:autoextend
データ ファイル仕様の完全構文は、ファイル名、そのサイズ、そしていくつかの任意の属性を含んでいます:
file_name:file_size[:autoextend[:max:max_file_size]]
autoextend
属性やそれらに続く物は、innodb_data_file_path
ライン内の最後のデータ
ファイルにのみ利用できます。
最後のデータ ファイルに autoextend
オプションを指定すると、InnoDB
はもしテーブルスペースの中に空き領域がなければデータ
ファイルを拡大します。デフォルトで、インクリメントは一回に付き8MB
となっています。それは
innodb_autoextend_increment
システム変数を変更する事で修正できます。
もしディスクがいっぱいになると、別のディスク上に別のデータ
ファイルを追加したくなるでしょう。項13.5.7. 「InnoDB データとログ
ファイルの追加と削除」
に既存のテーブル
スペースの再設定に関する説明があります。
InnoDB にはファイル
システムの最大サイズが分からないので、それが
2GB
のような小さい値の場合は注意してください。自動拡大データ
ファイルの最大サイズを指定するには、max
属性を利用してください。次の設定は、ibdata1
が最大500MB まで大きくなる事を許容します:
[mysqld] innodb_data_file_path=ibdata1:10M:autoextend:max:500M
InnoDB はデフォルトで MySQL データ
ディレクトリ内にテーブルスペース
ファイルを作成します。場所を明示的に指定するには、innodb_data_home_dir
オプションを利用してください。例えば、ibdata1
と ibdata2
と名づけられた2つのファイルを、/ibdata
ディレクトリ内で作成して利用するには、InnoDB
をこのように設定してください:
[mysqld] innodb_data_home_dir = /ibdata innodb_data_file_path=ibdata1:50M;ibdata2:50M:autoextend
注意:InnoDB
はディレクトリを作成しないので、サーバを起動する前に必ず
/ibdata
ディレクトリが存在する事を確認してください。これは、ご自分が設定する別のログ
ファイルにも全て当てはまります。必要なディレクトリを作成する為に、Unix
か DOS mkdir
コマンドを利用してください。
InnoDB は
innodb_data_home_dir
の値を原文どおりにデータ
ファイル名に連結させ、必要に応じてパス名セパレータ(スラッシュまたはバックスラッシュ)を値の間に追加して、各データ
ファイルのディレクトリ パスを形作ります。
もし innodb_data_home_dir
オプションについて my.cnf
内で全く触れられなければ、MySQL データ
ディレクトリを意味する 「dot」 directory
./ がデフォルト値になります。
(MySQL
サーバは、実行を始める時にその時起動しているディレクトリを、それ自体のデータ
ディレクトリに変更します。)
もし innodb_data_home_dir
を空の文字列として指定すれば、innodb_data_file_path
値内にリストされたデータ
ファイルに完全なパスを指定する事ができます。次の例は、前出の物と同等です:
[mysqld] innodb_data_home_dir = innodb_data_file_path=/ibdata/ibdata1:50M;/ibdata/ibdata2:50M:autoextend
シンプルなmy.cnf
例。128MB RAM
とハードディスクが1つあるコンピュータを持っていると仮定してください。
次の例は、autoextend
属性を含む、InnoDB の為の
my.cnf か、 my.ini
内で可能な設定パラメータを表しています。この例は、InnoDB
データ ファイルとログ
ファイルをいくつかのディスクに分散する事を希望しない、Unix
と Windows
両方のほとんどのユーザに適しています。これは、MySQL
データ ディレクトリ内に、自動拡大データ
ファイル ibdata1 と、2つの
InnoDB ログ ファイル
ib_logfile0 と
ib_logfile1 を作成します。
[mysqld] # You can write your other MySQL server options here # ... # Data files must be able to hold your data and indexes. # Make sure that you have enough free disk space. innodb_data_file_path = ibdata1:10M:autoextend # # Set buffer pool size to 50-80% of your computer's memory innodb_buffer_pool_size=70M innodb_additional_mem_pool_size=10M # # Set the log file size to about 25% of the buffer pool size innodb_log_file_size=20M innodb_log_buffer_size=8M # innodb_flush_log_at_trx_commit=1
MySQL サーバがデータ ディレクトリ内にファイルを作成する為の正当なアクセス権を持っている事を確認してください。さらに一般的には、サーバはデータ ファイルとログ ファイルを作成しなければいけないディレクトリ内にアクセス権を持っている必要があります。
データ ファイルはいくつかのファイル システム内で 2GB 以下でなければいけない事に注意してください。結合したログ ファイルのサイズは 4GB 以下でなければいけません。結合したデータ ファイルのサイズは最低 10MB でなければいけません。
InnoDB
テーブルスペースを初めて作成する時は、MySQL
サーバをコマンド
プロンプトから起動するのが一番良い方法です。その時
InnoDB
はデータベース作成に関する情報をスクリーンにプリントする事ができる為、何が起こっているかを知る事ができるのです。例えば、もし
Windows 上で mysqld が C:\Program
Files\MySQL\MySQL Server 5.1\bin
内にあったら、次ように起動する事ができます:
C:\> "C:\Program Files\MySQL\MySQL Server 5.1\bin\mysqld" --console
もしスクリーンにサーバ
アウトプットを送らないなら、InnoDB
がスタートアップ作業の最中に何をプリントするのかを確認する為にサーバのエラー
ログを確認してください。
InnoDB
によって表示される情報の例については、項13.5.5. 「InnoDB テーブルスペースを作成する」
を参照してください。
サーバが起動した時に読み込むオプション
ファイルの [mysqld]
グループ内にある InnoDB
オプションをおく事ができます。オプション
ファイルの場所に関しては、項3.3.2. 「オプションファイルの使用」
で紹介されています。
もし MySQL
をインストールと設定ウィザードを利用して
Windows 上にインストールしたら、そのオプション
ファイルはお使いの MySQL インストール
ディレクトリ内の my.ini
ファイルになります。詳しくは
項2.3.4.14. 「my.ini ファイルのロケーション」
を参照してください。
もしお使いの PC が、C:
ドライブがブート ドライブではないブート
ローダを利用していたら、残されたオプションは
Windows ディレクトリ(通常 C:\WINDOWS
か C:\WINNT)内の
my.ini
ファイルを利用する事だけです。WINDIR
の値をプリントするには、コンソール
ウィンドウ内のコマンド プロンプトで
SET
コマンドを利用する事ができます:
C:\> SET WINDIR
windir=C:\WINDOWS
mysqld
が特定のファイルからだけオプションを読み込むようにしたいのであれば、サーバを起動する時
--defaults-file オプションをコマンド
ラインの最初のオプションとして利用する事ができます:
mysqld --defaults-file=your_path_to_my_cnf
進歩した my.cnf
例。ディレクトリ パス
/、/dr2 そして
/dr3 に 2GB RAM と3つの 60GB ハード
ディスクを持つ Linux
コンピュータを持っていると仮定してください。
次の例は、InnoDB の
my.cnf
内で可能な設定パラメータを表しています。
[mysqld] # You can write your other MySQL server options here # ... innodb_data_home_dir = # # Data files must be able to hold your data and indexes innodb_data_file_path = /db/ibdata1:2000M;/dr2/db/ibdata2:2000M:autoextend # # Set buffer pool size to 50-80% of your computer's memory, # but make sure on Linux x86 total memory usage is < 2GB innodb_buffer_pool_size=1G innodb_additional_mem_pool_size=20M innodb_log_group_home_dir = /dr3/iblogs # innodb_log_files_in_group = 2 # # Set the log file size to about 25% of the buffer pool size innodb_log_file_size=250M innodb_log_buffer_size=8M # innodb_flush_log_at_trx_commit=1 innodb_lock_wait_timeout=50 # # Uncomment the next lines if you want to use them #innodb_thread_concurrency=5
場合によっては、もし全てのデータが同じディスク上に置かれていなければ、データベース性能が向上します。
ログ
ファイルをデータとは別のディスク上に置く事で、性能が向上する事が多いです。どのようにするかを例で説明しています。.これは、2つのデータ
ファイルを別々のディスクに、そしてログ
ファイルを3つ目のディスクにおきます。InnoDB
は最初のデータ
ファイルを先に利用してテーブル
スペースを埋めていきます。InnoDB
データ ファイルとして、未加工ディスク
パーティション(未加工デバイス)を利用する事ができ、そのおかげで
I/O
のスピードが向上します。項13.5.3.2. 「共有テーブルスペースに未加工デバイスを利用する」
を参照してください。
警告: 32-bit GNU/Linux x86
上では、メモリ使用を高く設定しすぎないように注意してください。glibc
はプロセス ヒープがスレッド
スタックよりも大きくなる事を許容する可能性があり、その為サーバがクラッシュしてしまうかもしれません。もし次の式の値が2GB
に近い、またはそれを上回っていたら危険です:
innodb_buffer_pool_size + key_buffer_size + max_connections*(sort_buffer_size+read_buffer_size+binlog_cache_size) + max_connections*2MB
各スレッドはスタック(通常2MB ですが、MySQL AB
バイナリ内ではたったの256KB)を利用し、そして最悪の場合、sort_buffer_size
+ read_buffer_size 追加メモリも利用します。
MySQL
をご自分でコンパイルする事により、32ビット
Windows 内で最高 64GB
の物理メモリを利用する事ができます。項13.5.4. 「InnoDB 起動オプションとシステム変数」
内の innodb_buffer_pool_awe_mem_mb
に関する説明を参照してください。
別の mysqld サーバ パラメータはどのように調整するのでしょう?次の値は典型的な物であり、ほとんどのユーザに適応しています:
[mysqld]
skip-external-locking
max_connections=200
read_buffer_size=1M
sort_buffer_size=1M
#
# Set key_buffer to 5 - 50% of your RAM depending on how much
# you use MyISAM tables, but keep key_buffer_size + InnoDB
# buffer pool size < 80% of your RAM
key_buffer_size=value
各 InnoDB
テーブルとそのインデックスをそれ自体のファイル内に格納する事ができます。この特徴は、実際に各テーブルがそのテーブルスペースを持つ為
「multiple tablespaces」 と呼ばれています。
複数のテーブルスペースを利用する事は、特定のテーブルを別々の物理ディスクに移動したり、単一テーブルのバックアップを残りの
InnoDB
テーブルの利用を邪魔する事なく、素早く復元したいユーザにとって、有益な物です。
このラインを my.cnf の
[mysqld]
セクションに追加する事で、複数のテーブルスペースを有効にする事ができます:
[mysqld] innodb_file_per_table
サーバを再起動した後、InnoDB
はテーブルが属するデータベース
ディレクトリ内にある、それ自体のファイル
tbl_name.ibdMyISAM ストレージ
エンジンが行う事と似ていますが、MyISAM
はテーブルをデータ ファイル
tbl_name.MYDtbl_name.MYIInnoDB
には、データとインデックスは
.ibd
ファイル内で一緒に格納されます。tbl_name.frm
もし innodb_file_per_table ラインを
my.cnf
から削除してサーバを再起動すると、InnoDB
は共有テーブルスペース
ファイル内にテーブルを再度作成します。
innodb_file_per_table
はテーブル作成だけに影響を与え、既存テーブルにアクセスはしません。もしこのオプションを利用してサーバを起動すると、新しいテーブルは
.ibd
ファイルを利用して作成されますが、共有テーブルスペース内に存在するテーブルにアクセスする事もまだ可能です。もしオプションを削除してサーバを再起動すると、新しいテーブルは共有テーブルスペース内に作成されますが、複数のテーブルスペースを利用して作成されたテーブルにもまだアクセスする事ができます。
注意:InnoDB
は、共有テーブルスペースに内部データ
ディレクトリと取り消しログを置くので、いつもそれを必要とします。.ibd
ファイルは InnoDB
の作動に充分ではありません。
注意:MyISAM
テーブル
ファイルで行えるのと同じように、データベース
ディレクトリ間で .ibd
ファイルを自由に移動させる事はできません。これは、InnoDB
共有テーブルスペース内に格納されているテーブル定義がデータベース名を含み、そして
InnoDB がトランザクション ID
とログ
シーケンス番号の一貫性を保持しなければいけない為です。
1つのデータベースから別のデータベースに
.ibd
ファイルとその関連テーブルを移動するには、RENAME
TABLE
ステートメントを利用してください:
RENAME TABLEdb1.tbl_nameTOdb2.tbl_name;
もし .ibd の 「空の」
バックアップを持っていれば、それを次のように、それが発生した場所から
MySQL インストールに格納する事ができます:
この
ALTER TABLEステートメントを発行してください:ALTER TABLE
tbl_nameDISCARD TABLESPACE;注意:このステートメントは現在の
.ibdファイルを削除します。バックアップ
.ibdファイルを正しいデータベース ディレクトリ内に戻してください。この
ALTER TABLEステートメントを発行してください:ALTER TABLE
tbl_nameIMPORT TABLESPACE;
このコンテキスト内で 「空の」
.ibd ファイル
バックアップが意味する物は:
.ibdファイル内には、トランザクションによってコミットされていない変更はありません。.ibdファイル内にマージされていない挿入バッファ エントリはありません。パージは
.ibdファイルから全ての削除マークされたインデックス レコードを削除しました。mysqld は、
.ibdファイルの全ての変更されたページをバッファ プールからファイルにフラッシュしました。
次の方法を利用して、空のバックアップ
.ibd
ファイルを作る事ができます:
mysqld サーバからの全てのアクティビティを停止して、全てのトランザクションをコミットしてください。
SHOW ENGINE INNODB STATUSがデータベース内にアクティブなトランザクションが無いと表示し、InnoDBのメイン スレッド ステータスがWaiting for server activityとなるまで待ってください。すると、.ibdファイルのコピーを作成する事ができます。
.ibd
ファイルの空のコピーを作成する別の方法は、商業
InnoDB Hot Backup
ツールを利用する事です:
InnoDBインストールをバック アップする為に InnoDB Hot Backup を利用してください。2番目の mysqld サーバをバック アップ上で起動し、その中で
.ibdファイルを掃除させてください。
共有テーブルスペース内で未加工ディスク パーティションをデータ ファイルとして利用できます。未加工ディスクを利用する事で、Windows といくつかの Unix システム上でファイル システムの負荷が無い非バッファ I/O を実行する事ができ、それで操作性能が向上します。
新しいデータ
ファイルを作成する時、innodb_data_file_path
内のデータ ファイル
サイズの直後にキーワード newraw
を置く必要があります。パーティションは、少なくても指定したサイズと同じである必要があります。ディスク仕様の
1MB
は通常1,000,000バイトを意味するのに対して、InnoDB
内の1MB は1024 × 1024
バイトである事に注意してください。
[mysqld] innodb_data_home_dir= innodb_data_file_path=/dev/hdd1:3Gnewraw;/dev/hdd2:2Gnewraw
次にサーバを起動する時、InnoDB
は newraw
キーワードに気付き、新しいパーティションを開始します。しかし、まだ
InnoDB
テーブルを作成したり変更したりしないでください。そうでなければ、サーバを次に再起動した時
InnoDB
がパーティションを再開始し、変更が全て失われます。(安全策として、InnoDB
は newraw
を持つパーティションが指定された時ユーザがデータを更新する事を防ぎます。)
InnoDB
が新しいパーティションを開始したら、サーバを停止し、データ
ファイル仕様の中の newraw を
raw に変更してください:
[mysqld] innodb_data_home_dir= innodb_data_file_path=/dev/hdd1:5Graw;/dev/hdd2:2Graw
そしてサーバを再起動させると、InnoDB
は変更を許可します。
Windows 上では、次のようにディスク パーティションを割り当てる事ができます:
[mysqld] innodb_data_home_dir= innodb_data_file_path=//./D::10Gnewraw
//./
は物理的ドライブにアクセスする為の Windows
の構文 \\.\ に対応しています。
未加工ディスク パーティションを利用する時、MySQL サーバを起動するのに利用されるアカウントによって読み込み書き込みアクセスが許可されている事を確認してください。
この章では、InnoDB
に関連するコマンド
オプションとシステム変数を紹介します。虚実であるシステム変数は、それらを名づける事によってサーバ起動時に有効にされるか、または
skip-
プリフィックスを利用する事で無効にされます。例えば、InnoDB
チェックサムを有効、または無効にするには、コマンド
ライン上で --innodb_checksums か
--skip-innodb_checksums
を、またはオプション ファイル内で
innodb_checksums か
skip-innodb_checksums
を利用する事ができます。数字値を取るシステム変数は、コマンド
ライン上で
--
として、またはオプション ファイル内で
var_name=valuevar_name=value
MySQL Enterprise MySQL ネットワーク モニタリングとアドバイス サービスは、InnoDB 起動オプションと関連するシステム変数に関する専門家のアドバイスを提供します。追加情報については http://www-jp.mysql.com/products/enterprise/advisors.html を参照してください。
InnoDB コマンド オプション:
InnoDB システム変数:
innodb_additional_mem_pool_sizeInnoDBがデータ辞書情報と別の内部データ構造を格納する為に利用する、メモリ プールのバイトでのサイズです。より多くのテーブルをアプリケーション内に持っていると、ここに割り当てる為により多くのメモリが必要になります。もしInnoDBがこのプール内のメモリを使い果たしてしまったら、これは OS からメモリを割り当て始め、MySQL エラー ログに警告メッセージを書きます。デフォルト値は1MB です。自動拡大テーブルスペースがいっぱいになった時にサイズを拡大する為のインクリメント サイズ(MB)。デフォルト値は8です。
AWE メモリ内に置かれた時の、バッファ プールのサイズ(MB)。これは32ビット Windows 内でだけ関連性があります。もしお使いの32ビット Windows OS が4GB 以上のメモリをサポートするなら、いわゆる 「Address Windowing Extensions,」 を利用する事で、この変数を利用して
InnoDBバッファプールを AWE 物理的メモリに割り当てる事ができます。この変数の最大可能値は63000です。 もしこれが0以上なら、innodb_buffer_pool_sizeはInnoDBがその AWE メモリを マップする mysqld の32ビット アドレス領域内のウィンドウです。innodb_buffer_pool_sizeの適正な値は 500MB です。AWE メモリを活用するには、自分で MySQL をリコンパイルする必要があります。これを行うのに必要な現在のプロジェクト設定は、
storage/innobase/os/os0proj.cソース ファイル内で見つける事ができます。InnoDBがそのテーブルのデータとインデックスをキャッシュする為に利用する、メモリバッファ のバイトでのサイズです。この値を大きく設定するほど、テーブル内のデータにアクセスするのに必要なディスク I/O は少なくなります。専用のデータベース サーバ上で、これをマシンの物理的メモリ サイズの最大80% に設定すると良いでしょう。しかし、物理的メモリの競合が OS 内でページングを引き起こす可能性があるので、あまり大きく設定しないでください。InnoDBは、壊れたハードウェアやデータ ファイルに対する追加フォールト トレランスを保証するディスクからの全てのページの読み込み上で、チェックサムの妥当性確認を利用する事ができます。この妥当性確認はデフォルトで有効化されています。しかし、まれに(ベンチマークが起動している時等 )、この追加安全機能は必要なく、--skip-innodb-checksumsを利用して無効にする事ができます。同時にコミットする事ができるスレッドの数。0の値は並行処理制御を無効にします。
InnoDBに同時に入る事ができるスレッドの数は、innodb_thread_concurrency変数によって決められます。スレッドがInnoDBに入ろうとする時にもし並行処理の限度までスレッド数が達していたら、それらは列になります。スレッドがInnoDBに入るのを許可されると、innodb_concurrency_ticketsの値と同等の 「フリー チケット」 をたくさん与えられ、スレッドはそのチケットを使ってしまうまでは自由にInnoDBに出入りできます。それ以降は、スレッドが次にInnoDBに入ろうとした時に、再度並行処理チェックの対象となります。(または列に並ぶ可能性もある)独立したデータ ファイルとそれらのサイズへのパス。各データ ファイルへの完全ディレクトリ パスは、ここに指定された各パスへの
innodb_data_home_dirを結合する事によって形作られます。ファイル サイズは、サイズ値にMかGを付加して、MB か GB (1024MB)で指定されます。ファイル サイズの合計は最低10MB 必要です。もしinnodb_data_file_pathを指定しなければ、デフォルト動作でibdata1と名づけられた10MB の単一自動拡大データ ファイルが作成されます。各ファイルのサイズ制限は OS によって決定されます。大きいファイルをサポートする OS のサイズを4GB 以上に設定する事ができます。未加工ディスク パーティションをデータ ファイルとして利用する事もできます。詳しくは 項13.5.3.2. 「共有テーブルスペースに未加工デバイスを利用する」 を参照してください。全ての
InnoDBデータ ファイルのディレクトリ パスの主な部分。もしこの値を設定しなければ、デフォルトは MySQL データ ディレクトリになります。値を空の文字列として指定する事もでき、その場合はinnodb_data_file_path内で完全なファイル パスを利用する事ができます。デフォルトで、
InnoDBは全てのデータを2回格納します。一回目は二重書き込み バッファに、そして次に実際のデータ ファイルに格納します。この変数はデフォルトで有効化されています。それは、データの整合性や起こり得る失敗に対する心配よりも、ベンチマークや最高性能が要求される時に、--skip-innodb_doublewriteを利用して止める事ができます。もしこの変数を0に設定すると、
InnoDBはシャットダウンの前に完全消去と挿入バッファ マージを行います。これらの操作には数分間、または極端な場合には数時間かかる事があります。もしこの変数を1に設定すると、InnoDBはこれらの操作をシャットダウンの時にスキップします。デフォルト値は1です。もしこれを2に設定すると、InnoDBはそのログをフラッシュし、まるで MySQL がクラッシュしたかのように急にシャットダウンします。コミットされたトランザクションはなくなりませんが、次の起動の際にクラッシュ復旧が行われます。 2の値は NetWare 上では利用できません。InnoDB内のファイル I/O スレッド数。通常、これはデフォルト値である4のままにしておくべきですが、Windows 上のディスク I/O にとってはそれよりも大きい値の方がよいかもしれません。Unix 上では、数値を増やしても効果はありません。InnoDBは必ずデフォルト値を利用します。この変数が有効になると、
InnoDBはデータとインデックスを共有テーブルスペースに格納するのではなく、それ自体の.ibdファイルを利用してそれぞれの新しいテーブルを作成し、そこに格納します。デフォルトでは、共有テーブルスペースにテーブルを作成するという事になっています。詳しくは 項13.5.3.1. 「Per-Table テーブルスペースを利用する」 を参照してください。innodb_flush_log_at_trx_commitinnodb_flush_log_at_trx_commitが0に設定された時は、ログ バッファは1秒に一回ログ ファイルに書き込まれ、ディスク操作へのフラッシュはログ ファイル上で行われますが、トランザクション コミットの際には何も行われません。この値が1(デフォルト)の時は、ログ ファイルは各トランザクション コミットの時にログ ファイルに書き込まれ、ディスク操作へのフラッシュはログ ファイル上で行われます。2に設定された時は、ログ バッファはコミット毎にファイルに書き込まれますが、ディスク操作へのフラッシュはそこでは行われません。しかし、値が2の時もログ ファイル上でのフラッシュは1秒に1回行われます。1秒に1回のフラッシュは、処理スケジュールの発行の為100% 保証された物ではないという事に注意してください。この変数のデフォルト値は1です。これは ACID 整合性に要求されている値です。より良い性能の為に1以外の値を設定する事もできますが、その場合1つのクラッシュの中で最大1秒分のトランザクションを失う可能性があります。もし値を0に設定すると、全ての mysqld プロセス クラッシュは最後の秒のトランザクションを消す場合があります。もし値を2に設定すると、OS のクラッシュか停電によって、最後の秒のトランザクションが消されてしまいます。 しかし、
InnoDBのクラッシュ復旧は影響を受けないので、値に関係なくクラッシュ復旧は行われます。多くの OS といくつかのディスク ハードウェアはディスクへのフラッシュ操作を欺く事があると覚えておいてください。それらはフラッシュが行われていなくても、行われたと mysqld に伝える可能性があります。1の設定がしてあってもトランザクションの耐久力が保証されないという事になり、さらに悪い事に、停電によってInnoDBデータベースが破損する可能性もあります。SCSI ディスク コントローラ内やディスク自体の中での、バッテリーに頼っているディスク キャッシュの利用はファイル フラッシュのスピートを上げ、操作を安全に行う事ができます。ハードウェア キャッシュ内でディスク書き込みのキャッシュを無効にする為に、Unix コマンド hdparm を利用してみたり、ハードウェア ベンダに対しての特定の別のコマンドを利用したりもできます。注意:
InnoDBとトランザクションを共に利用して複製設定内で最大の耐久力と一貫性を得る為に、お使いのマスタ サーバmy.cnf内でinnodb_flush_log_at_trx_commit=1とsync_binlog=1を利用しなければいけません。もし
fdatasync(デフォルト)に設定すると、InnoDBはデータとログ ファイルの両方をフラッシュする為にfsync()を利用します。もしO_DSYNCに設定すると、InnoDBはログ ファイルをオープン、フラッシュする為にO_SYNCを利用しますが、データ ファイルをフラッシュする為にはfsync()を利用します。もしO_DIRECTが指定されると(GNU/Linux バージョン上で有効)、InnoDBはデータ ファイルをオープンする為にO_DIRECTを利用し、データとログ ファイルの両方をフラッシュする為にfsync()を利用します。InnoDBはfdatasync()の代わりにfsync()を利用する事、また様々な種類の Unix 上で問題があった為、デフォルトでO_DSYNCは利用しないという事に注意してください。この変数は Unix に対してだけ関連があります。Windows 上では、フラッシュの方法は毎回async_unbufferedで、変更する事はできません。この変数の異なる値は
InnoDB performance上で著しい影響を持ちます。例えば、InnoDBデータとログ ファイルが SAN 上に位置するいくつかのシステム上では、innodb_flush_methodをO_DIRECTに設定する事は、3つの要因によってシンプルなSELECTステートメントの性能を劣らせる可能性があるという事が発見されました。クラッシュ復旧モード。警告:この変数は、破損したデータベースからテーブルを捨てたいという緊急の場合のみ、0以降の値に設定しなければいけません!可能な値は1から6です。これらの値の意味は、項13.5.8.1. 「
InnoDB復旧の強制」 で説明されています。安全策として、InnoDBはこの変数が0以上の時はそのデータへの変更を阻止します。InnoDBトランザクションがロール バックされる前に、ロックを待つ秒数でのタイムアウト。InnoDBは自動的にそれ自体のロック テーブル内でトランザクション デッドロックを検出し、トランザクションをロールバックします。InnoDBはLOCK TABLESステートメントを利用してロック セットを通知します。デフォルトは50秒です。innodb_locks_unsafe_for_binlogこの変数は
InnoDBサーチとインデックス スキャン内でネクスト キー ロックをコントロールします。デフォルトによってこの変数は0(無効)であり、それはネクスト キー ロックが有効であると意味します。通常、
InnoDBは next-key locking と呼ばれるアルゴリズムを利用します。InnoDBは、それがテーブル インデックスを検索やスキャンする時に、遭遇した全てのインデックス レコード上で共有または専用ロックを設定する、という方法で行レベル ロックを実行します。従って、行レベル ロックは実際はインデックス レコード ロックであるという事になります。InnoDBがインデックス レコード上で設定するロックは、そのインデックス レコードに先行する 「ギャップ」 にも影響を与えます。もしユーザがインデックス内のレコード R 上に共有または専用ロックを持っていたら、別のユーザはインデックスの順番で R の直前に新しいインデックス レコードを挿入する事はできません。この変数を有効にすると、InnoDBが検索やインデックス スキャン内でネクスト キー ロックを利用しないよう働きかけます。ネクスト キー ロックは外部キー制約と複製キー チェックを保証する為にはまだ利用されます。この変数を有効にすると、バグを引き起こす可能性がある事に注意してください:後で選択した行内のいくつかのカラムを更新するつもりで、100よりも大きい値の識別子を持つchildテーブルから全ての子供を読み、ロックしたいと仮定します:SELECT * FROM child WHERE id > 100 FOR UPDATE;
idカラム上にインデックスがあると仮定してください。idが100以上の最初のレコードから、そのインデックスをクエリがスキャンします。もしインデックス レコード上に設定されたロックがギャップに挿入された物をロックしなければ、別のクライアントがテーブルに新しい行を挿入する事ができます。 もし同じトランザクション内で同じSELECTを実行すると、クエリから返された結果セット内に新しい行を見つける事ができます。これは、もしデータベースに新しい項目が追加されると、InnoDBはシリアリザビリティを保証しないという事も意味します。従って、もしこの変数が有効になると、InnoDBは最高の分離レベルREAD COMMITTEDを保証します。(コンフリクト シリアリザビリティは保証されたままです。)この変数を有効にすると、追加効果があります:
UPDATEやDELETE内のInnoDBは、更新や削除を行う行だけをロックします。このおかげでデッドロックの可能性が大幅に低くなりますが、それでもまだ起こります。この変数を有効にしても、UPDATEのような操作が別の似た操作(別のUPDATEのような) を追い越す事は、たとえそれらが別の行に影響を与えるとしても許されていない事に注意してください。このテーブルから始まる、次の例を検討してみてください:CREATE TABLE A(A INT NOT NULL, B INT) ENGINE = InnoDB; INSERT INTO A VALUES (1,2),(2,3),(3,2),(4,3),(5,2); COMMIT;
1つのクライアントがこれらのステートメントを実行すると仮定してください:
SET AUTOCOMMIT = 0; UPDATE A SET B = 5 WHERE B = 3;
そして、別のクライアントが、最初のクライアントの後にこれらのステートメントを実行すると仮定してください:
SET AUTOCOMMIT = 0; UPDATE A SET B = 4 WHERE B = 2;
この場合、2つ目の
UPDATEは、最初のUPDATEのコミットかロールバックを待つ必要があります。最初のUPDATEは行(2、3)上に専用ロックを持ち、2つ目のUPDATEも行をスキャンしている間に同じ行に専用ロックを得ようとしますが、それはできません。これは、2つのUPDATEのうち最初の物が行に専用ロックを得て、その行が結果セットに属しているかどうかを決める為に起こります。もしそうでなければ、それはinnodb_locks_unsafe_for_binlog変数が有効になった時に、不必要なロックを解除します。従って、
InnoDBは次のようにUPDATE1を実行します:x-lock(1,2) unlock(1,2) x-lock(2,3) update(2,3) to (2,5) x-lock(3,2) unlock(3,2) x-lock(4,3) update(4,3) to (4,5) x-lock(5,2) unlock(5,2)
InnoDBはUPDATE2を次のように実行します:x-lock(1,2) update(1,2) to (1,4) x-lock(2,3) - wait for query one to commit or rollback
InnoDBアーカイブ ファイルをログするかどうか。この変数は歴史的理由により存在していますが、利用はされていません。バックアップからの復旧は MySQL がそれ自身のログ ファイルを利用して行っていますので、InnoDBログ ファイルをアーカイブに保管する必要はありません。この変数のデフォルトは0です。InnoDBがディスク上のログ ファイルに書き込む為に利用するバッファのバイトでのサイズ。実用的な値の範囲は1MB から8MB です。デフォルトは1MB です。大きいログ バッファは、トランザクション コミットの前にディスクにログを書き込む必要なく、大きいトランザクションが起動する事を許容します。従って、もし大きいトランザクションを持っていたら、ログ ファイルを大きくしておく事でディスク I/O を節約する事ができます。ログ グループ内のそれぞれの長いファイルのバイトでのサイズ。ログ ファイルの結合したサイズは32ビット コンピュータ上で 4GB 以下でなければいけません。デフォルトは5MB です。実用的な値は、
Nがグループ内のログ ファイル数だとして、バッファ プールのサイズの1MB から 1/N-th です。 値が大きいほど、ディスク I/O を節約し、バッファ プール内で必要とされるチェックポイント フラッシュ活動は少なくなります。しかし、ログ ファイルが大きいという事はクラッシュした時の復旧のスピードが遅いという事も意味します。ログ グループ内のログ ファイル数。
InnoDBはファイルに輪状に書き込みをします。デフォルト(そして推奨)は2です。InnoDBログ ファイルへのディレクトリ パス。もしInnoDBログ変数を何も指定しなければ、デフォルトで MySQL データ ディレクトリ内にib_logfile0とib_logfile1という名前の2つの5MB ファイルを作成します。これは0から100の範囲の間の整数です。デフォルトは90です。
InnoDB内の主スレッドは、ダーティ (まだ書き込まれていない)ページの割合がこの値を超えないようにバッファ プールからページを書くように試みます。この変数は、消去操作が遅れている時に(項13.5.12. 「マルチバージョンの実装」 参照)
INSERT、UPDATEそしてDELETE操作をどのように遅らせるかをコントロールします。この変数のデフォルト値は0で、これは遅れは無いという事を意味します。InnoDBトランザクション システムはUPDATEかDELETE操作によって削除マークが付けられたインデックス レコードを持つトランザクションのリストを保持します。このリストの長さをpurge_lagにして下さい。purge_lagがinnodb_max_purge_lagを上回る時、各INSERT、UPDATEそしてDELETE操作は((purge_lag/innodb_max_purge_lag)×10)?5 ミリ秒遅れます。遅れは消去バッチの最初に、10秒ごとに計算されます。もし消去される行をを知る事ができる、古い一貫した読み取りビューの為に消去が起動しなかったら、その操作は遅れません。トランザクション サイズがたったの100バイトと小さく、テーブル内に消去されていない行を100MB 許容できると仮定した時、問題を引き起こす可能性のある作業負荷の典型的な設定は100万でしょう。
データベースの為に残すログ グループの同一コピー数。現在は、この値は1に設定しなければいけません。
この変数は
InnoDB内で複数のテーブルスペースを利用する場合のみ関連があります。それはInnoDBが同時にオープンしておける.ibdファイルの最大数を指定します。最大値は10です。デフォルトは300です。.ibdファイルに利用されるファイル記述子は、InnoDBに対しての物のみです。それらは、--open-files-limitサーバ オプションによって指定された物からは独立していて、テーブル キャッシュの操作に影響を与えません。MySQL 5.1 内で、
InnoDBはトランザクション タイムアウト上で最後のステートメントだけをロールバックします。このオプションが与えられると、トランザクション タイムアウトはInnoDBがトランザクション全体を異常終了し、ロールバックするよう働きかけます。(MySQL 4.1と同じ動作です。)この変数は、MySQL 5.1.15で追加されました。ONか1(デフォルト)に設定されると、この変数はInnoDBが XA トランザクション内の二相コミット サポートを有効にします。innodb_support_xaを有効にすると、トランザクションの準備でディスク フラッシュが余計に起こります。 XA を利用する事を気にしないのであれば、この変数をOFFか0に設定してこれを無効にする事ができ、ディスク フラッシュの数を減らし、InnoDB操作性能を向上させる事ができます。スレッドが、サスペンドされる前に
InnoDBミューテックスが開放されるのを待つ回数。もし
AUTOCOMMIT=0、InnoDBがLOCK TABLESを支持すると、MySQL は全てのスレッドがそれら全てのロックをテーブルにリリースするまでLOCK TABLE .. WRITEから戻りません。innodb_table_locksのデフォルト値は1です。それはもしAUTOCOMMIT=0ならLOCK TABLESは InnoDB がテーブルを内部的にロックするよう働きかける事を意味します。InnoDBは、この変数から与えられた制限よりも少ない、またはそれと同等の制限のInnoDB内部に多くの OS スレッドを一斉に保存しようと試みます。性能に関する問題を持ち、多くのスレッドがセマフォを待っているという事がSHOW ENGINE INNODB STATUSによって明らかにされたのなら、スレッド 「thrashing」 を持ち、この変数を低くまたは高く設定するよう試みる必要があります。もしたくさんのプロセッサとディスクがあるコンピュータをお持ちであれば、それを有効に活用する為に値を高く設定する事もできます。推奨値はお使いのシステムのプロセッサとディスク数の合計値です。この変数の範囲は0から1000です。20以上の値は無限並行処理として読み取られます。 無限というのは、並行チェックが無効になり、ミューテックスを獲得、リリースする事で発生するであろう、多量の負荷を防ぐという意味です。
MySQL 5.1.11以前はデフォルト値は20で、5.1.11以降は8となっています。
InnoDBスレッドはInnoDBの列に加わるまでに、マイクロ秒で何秒間スリープ状態にあるか。デフォルト値は10,000です。0の値ではスリープ状態にはなりません。sync_binlogもし変数値が正数であれば、MySQL サーバはバイナリ ログへの毎
sync_binlog書き込みごとに、ディスク(fdatasync())にそのバイナリ ログを同期化します。オート コミット モードでは、各ステートメントにつきバイナリ ログへの書き込みが1つあり、そうでなければ各トランザクションにつき1つの書き込みがあると覚えて置いてください。デフォルトは、ディスクへの同期化を行わない0です。 クラッシュしてしまった場合には、バイナリ ログから最大1つのステートメントかトランザクションが失われてしまう為、1の値が一番安全な値です。しかしこれは同時に、一番スピードが遅い物になります。(ディスクが、同期化の作業を大変速くする事ができる、バッテリで起動するキャッシュを搭載していない限り)
必要な InnoDB
設定パラメータを含む事ができるように、MySQLをインストールし、オプション
ファイルを編集したと仮定してください。MySQL
を起動する前に、InnoDB データ
ファイルとログ
ファイルの為に指定したディレクトリが存在する事、そしてMySQL
サーバがそれらのディレクトリにアクセスする権利がある事を確認しなければいけません。
InnoDB
はファイルだけを作成し、ディレクトリは作成しません。データとログ
ファイルの領域が充分である事も確認してください。
InnoDB
が有効な状態でサーバを初めて起動する時には、MySQL
サーバ mysqld は
mysqld_safe ラッパからや、Windows
サービスとしてではなく、コマンド
プロンプトから起動させるのが一番良いです。コマンド
プロンプトから起動する時、mysqld
が何をプリントするか、また何が起こっているかが分かります。Unix
上では、ただ mysqld
を呼び出して下さい。Windows
上では、--console
オプションを利用してください。
オプション ファイル内で初めて
InnoDB を設定した後 MySQL
サーバを起動する時、InnoDB
はデータ ファイルとログ
ファイルを作成し、次のような物をプリントします:
InnoDB: The first specified datafile /home/heikki/data/ibdata1 did not exist: InnoDB: a new database to be created! InnoDB: Setting file /home/heikki/data/ibdata1 size to 134217728 InnoDB: Database physically writes the file full: wait... InnoDB: datafile /home/heikki/data/ibdata2 did not exist: new to be created InnoDB: Setting file /home/heikki/data/ibdata2 size to 262144000 InnoDB: Database physically writes the file full: wait... InnoDB: Log file /home/heikki/data/logs/ib_logfile0 did not exist: new to be created InnoDB: Setting log file /home/heikki/data/logs/ib_logfile0 size to 5242880 InnoDB: Log file /home/heikki/data/logs/ib_logfile1 did not exist: new to be created InnoDB: Setting log file /home/heikki/data/logs/ib_logfile1 size to 5242880 InnoDB: Doublewrite buffer not found: creating new InnoDB: Doublewrite buffer created InnoDB: Creating foreign key constraint system tables InnoDB: Foreign key constraint system tables created InnoDB: Started mysqld: ready for connections
この時点で InnoDB
はテーブルスペースとログ
ファイルを初期化しました。mysql
のように、通常の MySQL クライアント
プログラムを利用して MySQL
サーバに接続する事ができます。MySQL サーバを
mysqladmin shutdown
を利用して終了する時、アウトプットは次のようになります:
010321 18:33:34 mysqld: Normal shutdown 010321 18:33:34 mysqld: Shutdown Complete InnoDB: Starting shutdown... InnoDB: Shutdown completed
データ ファイルとログ ディレクトリを見ると、そこに作成されたファイルを確認する事ができます。MySQL が再起動する時、データ ファイルとログ ファイルは既に作成されているので、アウトプットはさらにブリーフな物になっています:
InnoDB: Started mysqld: ready for connections
もし innodb_file_per_table オプションを
my.cnf
に追加すると、InnoDB
は、.frm
ファイルが作成されたのと同じ MySQL
データベース ディレクトリ内の
.ibdファイル内に各テーブルを格納します。詳しくは
項13.5.3.1. 「Per-Table テーブルスペースを利用する」
を参照してください。
もしファイル操作の最中に InnoDB
が OS
エラーをプリントすると、通常はその問題は次のうちどれかになります:
InnoDBデータファイル ディレクトリかInnoDBログ ディレクトリを作成しなかった。mysqld がそれらのディレクトリ内にファイルを作成するアクセス権を持っていない。
mysqld は正しい
my.cnfかmy.iniオプション ファイルを読み込む事ができず、その結果指定したオプションを見る事ができません。ディスクが一杯か、ディスク割当量を超えました。
指定したデータ ファイルと同じ名前のサブディレクトリを作成したので、その名前をファイル名として利用する事はできません。
innodb_data_home_dirかinnodb_data_file_path値内に構文エラーがあります。
InnoDB
がそのテーブルスペースかログ
ファイルを初期化しようとした時に何かが失敗すると、InnoDB
によって作成されたファイル全てを削除しなければいけません。これは、全ての
ibdata ファイルと全ての
ib_logfile
ファイルの事です。既にいくつかの
InnoDB
テーブルを作成していた場合、MySQL
データベース
ディレクトリからも、それらのテーブルの対応する
.frm ファイル
(もし複数のテーブルスペースを利用していたら全ての
.ibd
ファイルも)を削除してください。そして、InnoDB
データベースの作成にもう一度挑戦できます。何が起きているのか確認できるように、MySQL
サーバをコマンド
プロンプトから起動するのが一番良いです。
InnoDB
テーブルを作成する為には、CREATE
TABLE ステートメント内で ENGINE =
InnoDB オプションを指定してください:
CREATE TABLE customers (a INT, b CHAR (20), INDEX (a)) ENGINE=InnoDB;
このステートメントは、my.cnf
内で指定したデータ ファイルで構成されている
InnoDB テーブルスペース内のカラム
a
上でテーブルとインデックスを作成します。さらに、MySQL
は MySQL データベース ディレクトリ下の
test ディレクトリ内でファイル
customers.frm
を作成します。内部的に、InnoDB
はそれ自体のデータ
ディレクトリのテーブルにエントリを追加します。そのエントリはデータベース名を含んでいます。例えば、もし
test が customers
テーブルが作成されたデータベースであれば、エントリは
'test/customers'
の為の物になります。これは、他のいくつかのデータベース内で、同名
customers
のテーブルを作成する事ができ、そしてそのテーブル名は
InnoDB
内で衝突しないという事を意味します。
InnoDB テーブルに SHOW TABLE
STATUS
ステートメントを発行する事で、InnoDB
テーブルスペース内の空き領域の量をクエリする事ができます。SHOW
TABLE STATUS のアウトプット内の
Comment
セクション内に現れるテーブルスペース内の空き領域の量。例:
SHOW TABLE STATUS FROM test LIKE 'customers'
SHOW が InnoDB
テーブルの為に表示する統計は単なる概算であるという事に注意してください。それらは
SQL
最適化の中で利用されます。しかしテーブルやインデックスの、準備されていたバイトでのサイズは正確です。
デフォルトによって、MySQL
サーバに接続する各クライアントが、実行すると全ての
SQL
ステートメントを自動的にコミットするオート
コミットが有効な状態で開始します。複数ステートメント
トランザクションを利用する為に、SQL
ステートメント SET AUTOCOMMIT = 0
を利用してオートコミットをオフにし、トランザクションをコミットまたはロールバックする為に
COMMIT と ROLLBACK
を利用する事ができます。オートコミットをオンの状態のままにしておきたければ、トランザクションを
START TRANSACTION
と、COMMIT か ROLLBACK
のどちらかで囲む事ができます。次の例は2つのトランザクションを表しています。最初の物はコミットされ、2つ目の物はロールバックされています。
shell>mysql testmysql>CREATE TABLE CUSTOMER (A INT, B CHAR (20), INDEX (A))->ENGINE=InnoDB;Query OK, 0 rows affected (0.00 sec) mysql>START TRANSACTION;Query OK, 0 rows affected (0.00 sec) mysql>INSERT INTO CUSTOMER VALUES (10, 'Heikki');Query OK, 1 row affected (0.00 sec) mysql>COMMIT;Query OK, 0 rows affected (0.00 sec) mysql>SET AUTOCOMMIT=0;Query OK, 0 rows affected (0.00 sec) mysql>INSERT INTO CUSTOMER VALUES (15, 'John');Query OK, 1 row affected (0.00 sec) mysql>ROLLBACK;Query OK, 0 rows affected (0.00 sec) mysql>SELECT * FROM CUSTOMER;+------+--------+ | A | B | +------+--------+ | 10 | Heikki | +------+--------+ 1 row in set (0.00 sec) mysql>
PHP、Perl DBI、JDBC、ODBC、または MySQL
のスタンダード C
呼び出しインターフェースのような API
内では、COMMIT
のようなトランザクション コントロール
ステートメントを SELECT や
INSERT のような別の SQL
ステートメントのような文字列として、MySQL
サーバに送る事ができます。いくつかの API
は、別々の特別トランザクション
コミットやロールバック機能または方法も提供します。
重要:mysql
データベース(user や
host のような)内の MySQL システム
テーブルを InnoDB
タイプに変換しないでください。これはサポートされていない操作です。システム
テーブルは必ず MyISAM
タイプの物でなければいけません。
もし全ての(非システムの)テーブルを
InnoDB
テーブルとして作成したければ、サーバ
オプション ファイルの [mysqld]
セクションにライン
default-storage-engine=innodb
を追加するだけでよいです。
InnoDB は、MyISAM
ストレージ
エンジンがするのと同じように、インデックスを別々に作成する為の特別な最適化を行いません。従って、テーブルをエクスポート、インポートしたり、後でインデックスを作成したりはしません。テーブルを
InnoDB
に変換する一番早い方法は、InnoDB
テーブルに直接挿入する事です。それは、ALTER
TABLE ... ENGINE=INNODB
を利用する、または同一定義を利用して空の
InnoDB
テーブルを作成し、INSERT INTO ... SELECT *
FROM ...
を利用して行を挿入するという事です。
もし2番目のキー上に UNIQUE
制限があったら、インポート操作の最中に一時的に一意性チェックを切り、テーブル
インポートのスピードを上げる事ができます:
SET UNIQUE_CHECKS=0;
... import operation ...
SET UNIQUE_CHECKS=1;
大きいテーブルに対しては、InnoDB
が2番目のインデックス
レコードをバッチとして書く為にそれ自身の挿入バッファを利用する事ができるので、この作業をするとディスク
I/O
を大幅に節約する事ができます。データが複製キーを含んでいない事を必ず確認してください。UNIQUE_CHECKS
はストレージエンジンが複製キーを無視する事を許可しますが、それを要求はしません。
挿入の操作性をあげる為には、大きいテーブルを細かく分けて挿入するのが良いでしょう:
INSERT INTO newtable SELECT * FROM oldtable WHERE yourkey > something AND yourkey <= somethingelse;
全てのレコードが挿入された後で、テーブルをリネームする事ができます。
大きいテーブルの変換の最中に、ディスク I/O
を減らす為に InnoDB バッファ
プールのサイズを増やす必要があります。しかし、物質的メモリの80%
以上は利用しないでください。InnoDB
ログ ファイルのサイズを増やす事もできます。
テーブルスペースを一杯にしないように注意してください:InnoDB
テーブルは MyISAM
テーブルよりも多くのディスク領域を必要とします。もし
ALTER TABLE
操作で領域を使い切ってしまうと、それはロールバックを始め、それがディスクに頼っている場合何時間も時間がかかります。挿入には、InnoDB
はバッチ内のインデックスに2つ目のインデックス
レコードをマージする為に挿入バッファを利用します。それでディスク
I/O
を大幅に節約する事ができます。ロールバックにはそのような構造は利用されず、挿入の30倍の時間がかかります。
ロールバックが暴走した場合は、データベースに貴重なデータがなければ、膨大なディスク
I/O の完了を待つよりも、データベース
プロセスを強制終了したほうが良いでしょう完全な手順に関しては、項13.5.8.1. 「InnoDB 復旧の強制」
を参照してください。
もし InnoDB テーブルに
AUTO_INCREMENT
カラムを指定すると、InnoDB
データ ディレクトリ内のテーブル
ハンドルは、カラムに新しい値を割り当てるのに利用される自動インクリメント
カウンタと呼ばれる特別なカウンタを含みます。このカウンタは、ディスク上には格納されず、主メモリ内だけに格納されます。
InnoDB は、ai_col
を名づけた AUTO_INCREMENT
カラムを含むテーブル T
に自動インクリメント
カウンタを初期化する為に、次のアルゴリズムを利用します:サーバの起動の後で、テーブル
T
への最初の挿入をする為に、InnoDB
はこのステートメントと同等な物を実行します:
SELECT MAX(ai_col) FROM T FOR UPDATE;
InnoDB
はステートメントによって値が取り出された物によってインクリメントし、それをカラムとテーブルの自動インクリメント
カウンタに割り当てます。もしテーブルが空だったら、InnoDB
は値 1
を利用します。もしユーザがテーブル
T の為のアウトプットを表示する
SHOW TABLE STATUS
ステートメントを呼び出し、自動インクリメント
カウンタがまだ初期化されていなかったら、InnoDB
は値を初期化するがインクリメントはせず、そしてそれを後で挿入に利用する為に格納します。この初期化はテーブル上で通常の専用ロック読み込みを利用し、そのロックはトランザクションの最後まで続くという事に注意してください。
InnoDB
は、作成されたばかりのテーブルの為に自動インクリメント
カウンタを初期化するのと同じ手順に従います。
自動インクリメント
カウンタが初期化された後、もしユーザが
AUTO_INCREMENT
カラムの値を明示的に指定しなければ、InnoDB
はカウンタを1でインクリメントしカラムに新しい値を割り当てます。もしユーザがカラム値を明示的に指定する行を挿入し、それが現在のカウンタ値よりも大きければ、カウンタは指定されたカラムに設定されます。
もしカウンタを利用して生成された数値を持つトランザクションをロールバックすると、AUTO_INCREMENT
に割り当てられた値のシーケンス内のギャップに気がつくでしょう。
もしユーザが NULL か
0 を INSERT 内の
AUTO_INCREMENT
カラムに指定すると、InnoDB
は、値が指定されず、新しい値も生成されていないかのように行を扱います。
自動インクリメント構造の性能は、もしユーザがカラムにマイナスの値を割り当てたり、もし値が指定した整数タイプ内に格納する事ができる最大値を上回っていたりすると、定義できません。
自動インクリメント
カウンタにアクセスする時、InnoDB
は、トランザクションの最後までではなく、現在の
SQL
ステートメントの最後まで続く、特別なテーブル
レベル AUTO-INC
ロックを利用します。AUTO_INCREMENT
カラムを含んでいるテーブルへの挿入の並行処理を向上させる為に、特別ロック
リリース戦略が紹介されました。それにもかかわらず、2つのトランザクションは
AUTO-INC
ロックが長時間保持されればパフォーマンス
インパクトを与える事ができる
AUTO-INC
ロックを同じテーブル上で同時に持つ事ができません。
これは、1つのテーブルから全ての行を別のテーブルに挿入する
INSERT INTO t1 ... SELECT ... FROM t2
のようなステートメントのような場合の事です。
InnoDB
はサーバが起動している限り、メモリ内の自動インクリメント
カウンタを利用します。サーバが停止し再起動した時、先ほど説明があったように、InnoDB
は、テーブルへの最初の INSERT
に対する各テーブルのカウンタを再初期化します。
InnoDB
は、初期カウンタ値を設定したり、現在のカウンタ値を変更する為に、CREATE
TABLE と ALTER TABLE
ステートメント内の AUTO_INCREMENT =
テーブル
オプションをサポートします。このセクションの最初の方で説明があったとおり、このオプションの効果はサーバの再起動によって無くなってしまいます。
N
InnoDB は
外部キー制約もまたサポートします。InnoDB
内の外部キー制約定義の構文は次のようになります:
[CONSTRAINTsymbol] FOREIGN KEY [id] (index_col_name, ...) REFERENCEStbl_name(index_col_name, ...) [ON DELETE {RESTRICT | CASCADE | SET NULL | NO ACTION}] [ON UPDATE {RESTRICT | CASCADE | SET NULL | NO ACTION}]
外部キー定義には次のような条件があります:
両方のテーブルは
InnoDBテーブルである必要があり、それらはTEMPORARYテーブルではいけません。参照表の中では、外部キーカラムが同じ順番で first カラムとしてリストされているインデックスが存在する必要があります。もしそのようなインデックスが無ければ、自動的に参照表上に作成されます。
参照表の中では、参照カラムが同じ順番で first カラムとしてリストされているインデックスが存在する必要があります。
外部キー カラム上のインデックス プリフィックスはサポートされていません。この1つの結論は、それらのカラム上のインデックスは常にプリフィックス長を含む必要がある為、
BLOBとTEXTカラムを外部キー内に含む事ができないという事です。もし
CONSTRAINT条項が与えられると、symbolsymbol値はデータベース上で固有である必要があります。もし条項が与えられなければ、InnoDBは名前を自動的に作成します。
もし親テーブル内に適合する候補キー値が無ければ、InnoDB
は子テーブル内に外部キー値を作成しようとする
INSERT か UPDATE
操作を拒絶します。子テーブル内にいくつかの適合する行を持つ親テーブル内で、候補キー値を更新または削除しようとする
UPDATE や DELETE
操作に対して InnoDB
が取るアクションは、FOREIGN KEY
条項の ON UPDATE と ON
DELETE サブ条項を利用して指定された
referential action
上で依存しています。ユーザが親テーブルから行を削除または更新しようとして、子テーブル内に1つ以上の適合する行がある時、InnoDB
は取るべきアクションを考慮して5つのオプションをサポートします:
CASCADE:親テーブルから行を削除または更新し、子テーブル内で自動的に適合行を削除または更新します。ON DELETE CASCADEとON UPDATE CASCADEの両方がサポートされています。2つのテーブルの間で、親テーブル内、または子テーブル内で同じカラム上に機能するいくつかのON UPDATE CASCADE条項を定義するべきでは有りません。SET NULL:親テーブルから行を削除または更新し、子テーブル内で外部キー カラムをNULLに設定します。これは外部キー カラムが指定されたNOT NULL修飾子を持たない時だけ有効です。ON DELETE SET NULLとON UPDATE SET NULL条項の両方がサポートされています。NO ACTION:スタンダード SQL 内で、NO ACTIONは、もし参照表内に関連する外部キーがあれば主キー値を削除または更新しようとする事は許容されていないという意味で、 no action を意味します。InnoDBは親テーブルの削除または更新操作を拒否します。RESTRICT:親テーブルの削除または更新操作を拒否します。NO ACTIONとRESTRICTはON DELETEかON UPDATE条項を省略する事と同じです。(いくつかのデータベース システムが据え置きチェックを持ち、NO ACTIONが据え置きチェックです。MySQL 内では、外部キー制約は即座に確認されるので、NO ACTIONとRESTRICTは同じです。)SET DEFAULT:このアクションはパーサによって認識されますが、InnoDBはON DELETE SET DEFAULTかON UPDATE SET DEFAULT条項を含むテーブル定義を拒否します。
InnoDB
がテーブル内で外部キー制約をサポートする事に注意してください。これらのような場合、「子テーブル
レコード」
は本当に同じテーブル内で依存レコードを参照します。
InnoDB は、外部キー
チェックが速くなり、テーブル
スキャンを必要としないよう、外部キーと参照キー上にインデックスを要求します。外部キー上のインデックスは自動的に作成されます。これは、いくつかの古いバージョン内での、インデックスが明示的に作成される必要があり、そうでなければ外部キー制約の作成が失敗する、という物とは対照的です。
タイプ変換をせずに比較できるよう、外部キーと参照キー内の対応するカラムは
InnoDB 内に類似内部データ
タイプを持つ必要があります。整数タイプのサイズとサインは同じである必要があります。文字列タイプの長さは同じである必要はありません。もし
SET NULL アクションを指定したら、
子テーブル内のカラムを NOT
NULL
として宣言していない事を確認してください。
もし MySQL が CREATE
TABLEステートメントからエラー番号1005を報告し、そのエラーメッセージがエラー150を参照していたら、外部キー制約が正しく形作られていない為にテーブル作成は失敗します。
同じように、もし ALTER TABLE
が失敗し、それがエラー150を参照していたら、それは変更したテーブルに対して外部キー制約が間違って形作られるという意味になります。
サーバ内に一番新しい InnoDB
外部キー エラーの詳細説明を表示する為に
SHOW ENGINE INNODB STATUS
を利用する事ができます。
注意:InnoDB
は NULL
カラムを含む外部キーや参照キー上で外部キー制約を確認しません。
注意:トリガは現在、転送された外部キー アクションによって有効化されません。
内部 InnoDB
カラムの名前と一致するカラム名を持つテーブルを作成する事はできません。(DB_ROW_ID、DB_TRX_ID、DB_ROLL_PTR
そして DB_MIX_ID を含む)MySQL
5.1.10以前のバージョン内ではこれはクラッシュの原因となり、5.1.10からはサーバがエラー1005を報告し、エラーメッセージ内で
errno -1 を参照します。
SQL
スタンダードからの逸脱:InnoDB
は同じ参照キー値を持つ親テーブル内にいくつかの行があると、外部キーチェック内で同じキー値を持つ別の親行がまるで存在しないかのように機能します。例えば、もし
RESTRICT
タイプ制約を定義し、いくつかの親行を持つ子行があれば、InnoDB
はそれらの親行の削除を許可しません。
InnoDB
は、外部キー制約に対応するインデックス内のレコードに基づいた、縦型アルゴリズムを通して転送操作を行います。
SQL
スタンダードからの逸脱:非
UNIQUE キーを参照する FOREIGN
KEY 制約はスタンダード SQL
ではありません。それはスタンダード SQL への
InnoDB 拡張子です。
SQL
スタンダードからの逸脱:もし ON
UPDATE CASCADE か ON UPDATE SET
NULL が転送の最中に既に更新された
同じテーブル
の更新を反復すると、それは
RESTRICT
のように機能します。これは、自己参照型
ON UPDATE CASCADE か ON UPDATE SET
NULL
操作を利用する事ができないという意味です。これは転送更新の結果に起きる無限ループを防ぐ為の物です。反対に、自己参照型
ON DELETE SET NULL は、自己参照型
ON DELETE CASCADE
と同様可能です。転送操作は15レベルより深くネスト化される事はないでしょう。
SQL
スタンダードからの逸脱:通常の MySQL
のように、挿入、削除、または多くの行の更新を行う
SQL ステートメント内では、InnoDB
は UNIQUE と FOREIGN KEY
制約を行ごとに行います。SQL
スタンダードによると、デフォルト動作は据え置きチェックでなければいけません。それは、SQL
ステートメント全体
が処理された後に制約の確認だけが行われるいう事です。InnoDB
が据え置き制約チェックを実装するまでは、外部キーを通してそれ自身を参照するレコードを削除するというような、いくつかの操作を行う事が不可能になります。
ここに、単一カラム外部キーを通して
parent と child
テーブルを関連させるシンプルな例があります:
CREATE TABLE parent (id INT NOT NULL,
PRIMARY KEY (id)
) ENGINE=INNODB;
CREATE TABLE child (id INT, parent_id INT,
INDEX par_ind (parent_id),
FOREIGN KEY (parent_id) REFERENCES parent(id)
ON DELETE CASCADE
) ENGINE=INNODB;
product_order
テーブルが別の2つのテーブルに外部キーを持つ、さらに複雑な例。1つの外部キーが
product
テーブル内の2段インデックスに参照をつけます。その他の物は
customer テーブル内で単一カラム
インデックスに参照をつけます:
CREATE TABLE product (category INT NOT NULL, id INT NOT NULL,
price DECIMAL,
PRIMARY KEY(category, id)) ENGINE=INNODB;
CREATE TABLE customer (id INT NOT NULL,
PRIMARY KEY (id)) ENGINE=INNODB;
CREATE TABLE product_order (no INT NOT NULL AUTO_INCREMENT,
product_category INT NOT NULL,
product_id INT NOT NULL,
customer_id INT NOT NULL,
PRIMARY KEY(no),
INDEX (product_category, product_id),
FOREIGN KEY (product_category, product_id)
REFERENCES product(category, id)
ON UPDATE CASCADE ON DELETE RESTRICT,
INDEX (customer_id),
FOREIGN KEY (customer_id)
REFERENCES customer(id)) ENGINE=INNODB;
InnoDB は ALTER TABLE
を利用してテーブルに新しい外部キー制約を追加する事を許容します:
ALTER TABLEtbl_nameADD [CONSTRAINTsymbol] FOREIGN KEY [id] (index_col_name, ...) REFERENCEStbl_name(index_col_name, ...) [ON DELETE {RESTRICT | CASCADE | SET NULL | NO ACTION}] [ON UPDATE {RESTRICT | CASCADE | SET NULL | NO ACTION}]
要求されたインデックスを最初に作成する事を忘れないでください。.ALTER
TABLE
を利用して、自己参照型外部キー制約をテーブルに追加する事もできます。
InnoDB
は外部キーをドロップする為の ALTER
TABLE の利用もサポートします。
ALTER TABLEtbl_nameDROP FOREIGN KEYfk_symbol;
もし外部キーを作成した時に FOREIGN
KEY 条項が CONSTRAINT
名を含んでいたら、外部キーをドロップする為にその名前を参照する事ができます。そうでなければ、fk_symbol
値は外部キーが作成された時に
InnoDB
によって内部的に生成されます。
外部キーをドロップしたい時にシンボル値を見つけるには、SHOW
CREATE TABLE
ステートメントを利用してください。例:
mysql>SHOW CREATE TABLE ibtest11c\G*************************** 1. row *************************** Table: ibtest11c Create Table: CREATE TABLE `ibtest11c` ( `A` int(11) NOT NULL auto_increment, `D` int(11) NOT NULL default '0', `B` varchar(200) NOT NULL default '', `C` varchar(175) default NULL, PRIMARY KEY (`A`,`D`,`B`), KEY `B` (`B`,`C`), KEY `C` (`C`), CONSTRAINT `0_38775` FOREIGN KEY (`A`, `D`) REFERENCES `ibtest11a` (`A`, `D`) ON DELETE CASCADE ON UPDATE CASCADE, CONSTRAINT `0_38776` FOREIGN KEY (`B`, `C`) REFERENCES `ibtest11a` (`B`, `C`) ON DELETE CASCADE ON UPDATE CASCADE ) ENGINE=INNODB CHARSET=latin1 1 row in set (0.01 sec) mysql>ALTER TABLE ibtest11c DROP FOREIGN KEY `0_38775`;
単一 ALTER TABLE
ステートメントの別々の条項の中に外部キーを追加したりドロップしたりはできません。別々のステートメントが要求されます。
InnoDB パーサは、FOREIGN KEY
... REFERENCES ...
条項内のテーブルとカラム識別子がバックフォート内で参照される事を許容します。(あるいは、もし
ANSI_QUOTES SQL
モードが有効であれば二重引用符を利用する事もできます。)InnoDB
パーサは、lower_case_table_names
システム変数の設定も考慮します。
InnoDB
はテーブルの外部キー定義を SHOW CREATE
TABLE
ステートメントのアウトプットの一部として返します:
SHOW CREATE TABLE tbl_name;
mysqldump はダンプ ファイルのテーブルの正しい定義も作成し、外部キーの事も忘れません。
次のようにテーブルの外部キー制約を表示する事もできます:
SHOW TABLE STATUS FROMdb_nameLIKE 'tbl_name';
外部キー制約はアウトプットの
Comment
カラム内にリストされています。
外部キー
チェックを行っている時、InnoDB
はそれが見なければいけない子または親レコード上に共有行レベル
ロックを設定します。 InnoDB
は直ちに外部キー制約を確認します。その確認はトランザクション
コミットに据え置きされません。
外部キー関係を持つテーブルのダンプ
ファイルの再ロードを簡単にする為に、mysqldump
は FOREIGN_KEY_CHECKS
を0に設定する為に自動的にダンプ
アウトプット内にステートメントを含みます。これは、ダンプが再ロードされた時にテーブルが特定の順番で再ロードされなければいけないという問題を防ぎます。この変数をマニュアルで設定する事も可能です:
mysql>SET FOREIGN_KEY_CHECKS = 0;mysql>SOURCEmysql>dump_file_name;SET FOREIGN_KEY_CHECKS = 1;
これは、もしダンプ
ファイルが外部キーに対して正しい順番でオーダされていないテーブルを含んでいたら、テーブルをどんな順番でインポートしてもよいと許容します。これはインポート操作のスピードも上げます。FOREIGN_KEY_CHECKS
を0に設定する事は、LOAD DATA と
ALTER TABLE
操作の最中に外部キー制約を無視する為にも役に立ちます。しかし、FOREIGN_KEY_CHECKS=0
であったとしても、InnoDB
は、カラムが非適合カラム
タイプの参照をつける外部キー制約の作成を許容しません。
InnoDB は、SET
FOREIGN_KEY_CHECKS=0
を行わない限り、FOREIGN KEY
制約によって参照を付けられたテーブルをドロップする事を許容しません。テーブルをドロップする時、その作成ステートメント内で定義された制約もまたドロップされます。
それは、もしドロップされたテーブルを再作成すると、それに参照をつける外部キー制約と同一の定義を持つはずです。それは右側のカラム名とタイプを持ち、先に述べたように参照キー上にインデックスを持つはずです。もしそれらが満たされなければ、MySQL はエラー番号1005を返し、エラー メッセージ内で errno 150を参照します。
MySQL 複製は、MyISAM
に対して機能するのと同じように
InnoDB
テーブルに機能します。スレーブ上のストレージ
エンジンがマスタ上の元のストレージ
エンジンと同じではない場合での方法で複製を利用する事も可能です。例えば、スレーブ上の
MyISAM テーブルに、マスタ上の
InnoDB
テーブルへの修正を複製する事ができます。
マスタに新しいスレーブを設定するには、InnoDB
テーブルの .frm
ファイルと同様に、InnoDB
テーブル スペースのコピーとログ
ファイルのコピーを作成し、そのコピーをスレーブに移動させなければいけません。もし
innodb_file_per_table
変数が有効であれば、.ibd
ファイルもコピーする必要があります。これを行う為の正しい手順については
項13.5.8. 「InnoDB
データベースのバックアップと復旧」 を参照して下さい。
もしマスタか既存スレーブを閉じる事ができるのであれば、InnoDB
テーブル スペースとログ
ファイルの完全なバックアップを取り、それをスレーブの設定の為に利用する事ができます。サーバを停止させずに新しいスレーブを作成するには、非フリー(商業用)
InnoDB
Hot Backup ツール
を利用する事もできます。
MyISAM
テーブルに対してだけ機能する LOAD TABLE
FROM MASTER ステートメントを利用して
InnoDB
に複製を設定する事はできません。2つ可能な回避方法があります:
マスタ上のテーブルをダンプし、ダンプ ファイルをスレーブ内にインポートしてください。
LOAD TABLEを利用して複製を設定する前に、tbl_nameFROM MASTERALTER TABLEをマスタ上で利用し、そして後でマスタ テーブルをtbl_nameENGINE=MyISAMInnoDBに変換する為にALTER TABLEを利用してください。しかし、定義が損失するのでこれは外部キー制約があるテーブルには利用しないで下さい。
マスタ上で失敗するトランザクションは複製に全く影響を与えません。MySQL
複製は、MySQL がデータを変更する SQL
ステートメントを書き込むバイナリ
ログに基づいています。失敗するトランザクション(例えば、外部キー違反の為、またはロールバックされる為)はバイナリ
ログに書き込まないので、スレーブに送られません。
詳しくは 項12.4.1. 「START
TRANSACTION、COMMIT、そして
ROLLBACK 構文」
を参照してください。
このセクションでは、InnoDB
テーブル
スペースがスペースを使いきってしまったり、ログ
ファイルのサイズを変更したい時に何ができるか説明しています。
InnoDB テーブル
スペースのサイズを増やす一番簡単な方法は、最初からこれを自動拡大として設定する事です。テーブル
スペース定義内の最後のデータ ファイルの
autoextend
属性を指定してください。すると
InnoDB
は領域を使い切ってしまった時、そのファイルのサイズを自動的に8MB
インクリメント増やします。インクリメントサイズは、MBで計られる
innodb_autoextend_increment
システム変数の値を設定する事で変更できます。
または、別のデータ
ファイルを追加する事でテーブル
スペースのサイズを増やす事ができます。これを行う為には、MySQL
サーバを閉じ、innodb_data_file_path
の最後に新しいデータ
ファイルを追加する為にテーブル
スペース設定を変更し、そしてサーバを再起動してください。
もし最後のデータ ファイルがキーワード
autoextend
で定義されていたら、テーブル
スペースの再設定の手順は、最後のデータ
ファイルがどのサイズまで成長するかを考慮する必要が有ります。データ
ファイルのサイズを求め、それを1024 × 1024
bytes (= 1MB)
の倍数の最近値まで丸め、そして丸めたサイズを
innodb_data_file_path
内で明示的に指定してください。すると別のデータ
ファイルを追加する事ができます。innodb_data_file_path
内の最後のデータ
ファイルだけが自動拡大として指定できるという事を覚えて置いてください。
ひとつの例として、テーブル
スペースが1つだけ自動拡大データ ファイル
ibdata1
を持っていると仮定してください:
innodb_data_home_dir = innodb_data_file_path = /ibdata/ibdata1:10M:autoextend
このデータ ファイルが、時間をかけて988MB まで成長したと仮定してください。ここに、元のデータ ファイルを非自動拡大に変更し、別の自動拡大データ ファイルを追加した後の設定ラインがあります:
innodb_data_home_dir = innodb_data_file_path = /ibdata/ibdata1:988M;/disk2/ibdata2:50M:autoextend
テーブル
スペース設定に新しいファイルを追加する時には、それが存在していない事を確認してください。InnoDB
はサーバを再起動する時にファイルを作成し、初期化します。
現在、データ ファイルをテーブルスペースから削除する事はできません。テーブル スペースのサイズを小さくするには、この手順を利用してください:
全ての
InnoDBテーブルをダンプする為に mysqldump を利用してください。サーバを停止してください。
全ての存在するテーブルスペース ファイルを削除してください。
新しいテーブルスペースを設定してください。
サーバを再起動してください。
ダンプ ファイルをインポートしてください。
InnoDB ログ
ファイルの数やサイズを変更したければ、次の指示に従ってください。利用する手順は
innodb_fast_shutdown
の値によって決まります:
もし
innodb_fast_shutdownが2に設定されなければ:MySQL サーバを停止し、エラー無しでシャットダウンした事を確認する必要があります。(ログ内に未処理のトランザクションの情報が無い事を保証する為)シャットダウンの際に何かが起きた場合、テーブルスペースを復旧する為に必要になるので、古いログ ファイルを安全な場所にコピーしておいてください。古いログ ファイルをログ ファイル ディレクトリから削除し、ログ ファイル設定を変更する為にmy.cnfを編集し、MySQL サーバを再起動してください。mysqld はログ ファイルが存在しない事を確認し、新しいものを作成している事を告げます。もし
innodb_fast_shutdownが2に設定されると:サーバをシャットダウンし、innodb_fast_shutdownを1に設定し、サーバを再起動してください。サーバは復旧を許可されます。そして、サーバをもう一度シャットダウンし、InnoDBログ ファイル サイズを変更する為に前出の項目で説明されている手順に従わなければいけません。innodb_fast_shutdownを2に設定し直し、サーバを再起動してください。
安全なデータベース管理の鍵は定期的にバックアップを取る事です。
InnoDB Hot Backup は InnoDB
データベースが起動している最中にバックアップを取る事ができるオンライン
バックアップ ツールです。InnoDB Hot
Backup
はデータベースをシャットダウンする必要が無く、ロックの設定も無く、通常のデータベースの処理を邪魔する事もありません。InnoDB
Hot Backup は MySQL
サーバが起動するコンピュータごとに、年間ライセンス料が
?390掛かる、無料ではない(商業用)アドオン
ツールです。詳細情報とスクリーンショットに関しては
InnoDB Hot
Backup home page を参照してください。
もし MySQL
サーバをシャットダウンする事ができるなら、テーブルを管理する為に
InnoDB
によって利用される全てのファイルで構成されているバイナリ
バックアップを作成する事ができます。次の手順に従って下さい:
MySQL サーバをシャットダウンし、エラーが発生していない事を確認してください。
全てのデータ ファイルを(
ibdataファイルと.ibdファイル) 安全な場所にコピーしてください。全ての
ib_logfileファイルを安全な場所にコピーしてください。my.cnf設定ファイルを安全な場所にコピーしてください。InnoDBテーブルの全ての.frmファイルを安全な場所にコピーしてください。
複製は InnoDB
テーブルと共に機能するので、ハイ
アベイラビリティを必要とするデータベース
サイトにデータベースのコピーを保管する為に、MySQL
複製性能を利用する事ができます。
今説明したようにバイナリ
バックアップを作成する事に追加して、mysqldump
を利用してテーブルのダンプを定期的に作成する必要があります。これは、バイナリ
ファイルは気づかない内に破損する事があるからです。ダンプされたテーブルは人間が解読可能なテキスト
ファイル内に格納されるので、テーブルの破損を見つける事は簡単になります。また、フォーマットが単純な為、深刻なデータ破損の可能性は小さいです。mysqldump
は、別のクライアントをロックアウトせずに一貫性のあるスナップショットを作る為に利用できる
--single-transaction
オプションも持ちます
InnoDB
データベースを今説明したばかりのバイナリ
バックアップから現在まで復旧できるようにする為には、バイナリ
ログがオンの状態で MySQL
サーバを起動させる必要があります。すると、ポイント
イン タイムの復旧を達成する為にバックアップ
データベースにバイナリ
ログを適応する事ができます:
mysqlbinlog yourhostname-bin.123 | mysql
MySQL
サーバのクラッシュから復旧する為のたった一つの要求事項は、再起動させる事です。InnoDB
は自動的にログを確認し、データベースの前進を現在まで実行します。InnoDB
はクラッシュした時に存在していなかった、コミットされていないトランザクションを自動的にロールバックします。復旧の最中に、mysqld
は次のようなアウトプットを表示します:
InnoDB: Database was not shut down normally. InnoDB: Starting recovery from log files... InnoDB: Starting log scan based on checkpoint at InnoDB: log sequence number 0 13674004 InnoDB: Doing recovery: scanned up to log sequence number 0 13739520 InnoDB: Doing recovery: scanned up to log sequence number 0 13805056 InnoDB: Doing recovery: scanned up to log sequence number 0 13870592 InnoDB: Doing recovery: scanned up to log sequence number 0 13936128 ... InnoDB: Doing recovery: scanned up to log sequence number 0 20555264 InnoDB: Doing recovery: scanned up to log sequence number 0 20620800 InnoDB: Doing recovery: scanned up to log sequence number 0 20664692 InnoDB: 1 uncommitted transaction(s) which must be rolled back InnoDB: Starting rollback of uncommitted transactions InnoDB: Rolling back trx no 16745 InnoDB: Rolling back of trx no 16745 completed InnoDB: Rollback of uncommitted transactions completed InnoDB: Starting an apply batch of log records to the database... InnoDB: Apply batch completed InnoDB: Started mysqld: ready for connections
もしデータベースが破損したり、ディスクが失敗したら、バックアップから復旧作業を行う必要があります。破損が起きた場合、まず最初に破損されていないバックアップを見つけなければいけません。ベース バックアップを復旧した後、バックアップが作成された後に実行された変更を格納する為に、mysqlbinlog と mysql を利用してバイナリ ログ ファイルから復旧を行ってください。
場合によっては、1つか複数の破損したテーブルをダンプ、ドロップ、または再作成するだけで充分な事も有ります。もちろん
CHECK TABLE
が全ての破損を検出する事はできませんが、テーブルが破損したかどうかを確認する為に
CHECK TABLE SQL
ステートメントを利用する事ができます。テーブルスペース
ファイル内のファイル領域管理のインテグリティを確認する為に、innodb_tablespace_monitor
を利用する事ができます。
場合によっては、明白なデータベース ページの破損は、OSがそれ自体のファイル キャッシュを破損している為に起きていて、ディスク上のデータは無傷な事があります。まず最初にコンピュータを再起動するのが一番良いでしょう。それを行う事で、データベース破損のように見えていたエラーを排除する事ができます。
もしデータベース
ページが破損したら、SELECT INTO
OUTFILE
を利用してデータベースからテーブルをダンプしたいかもしれません。通常、この方法で取得されたデータは無傷です。そうだとしても、破損によって
SELECT * FROM
ステートメントや tbl_nameInnoDB
バックグラウンド操作がクラッシュしたりアサートしたり、または
InnoDB
前進復旧がクラッシュしたり、という事が起こります。
しかし、バックグラウンドの操作を防いでいる間に、テーブルをダンプする事ができるように
InnoDB ストレージ
エンジンの起動を強制する事ができます。例えば、サーバを再起動する前に、オプション
ファイルの [mysqld]
セクションに次のラインを追加する事ができます:
[mysqld] innodb_force_recovery = 4
innodb_force_recovery
のゼロではない許容値が続きます。大きい数字は小さい数字の全ての予防策を含んでいます。もし最大4のオプション値を利用してテーブルをダンプする事ができれば、破損した独立ページ上のいくつかのデータが失われるだけなので、比較的に安全です。データベース
ページは既に廃止された状態で残されるので、6の値はさらに徹底的であり、Bツリーやその他のデータベース構造に更なる破損を引き起こす可能性があります。
1(SRV_FORCE_IGNORE_CORRUPT)破損ページを検出したとしてもサーバを起動させてください。テーブルをダンプする助けになるので、
SELECT * FROMが破損したインデックス レコードとページを飛び越えるようにして下さい。tbl_name2(SRV_FORCE_NO_BACKGROUND)主スレッドが起動するのを防いで下さい。もし消去操作の最中にクラッシュが起きそうであれば、この復旧値はそれを防ぎます。
3(SRV_FORCE_NO_TRX_UNDO)復旧後にトランザクション ロールバックを起動しないでください。
4(SRV_FORCE_NO_IBUF_MERGE)挿入バッファ マージ操作も避けてください。もしそれらがクラッシュしそうであれば、行わないでください。テーブル統計を計算しないでください。
5(SRV_FORCE_NO_UNDO_LOG_SCAN)データベースを起動する時に取り消しログを見ないで下さい:
InnoDBは不完全なトランザクションもコミットしたように扱います。6(SRV_FORCE_NO_LOG_REDO)復旧と共にログ前進を接続内で行わないでください。
それらをダンプする為にテーブルから
SELECT
する事ができ、または強制復旧が利用されたとしてもテーブルを
DROP か CREATE
する事ができます。もし与えられたテーブルがロールバック上でクラッシュを引き起こしていると知ったら、それをドロップする事ができます。大量の失敗インポートや
ALTER TABLE
によって引き起こされた暴走ロールバックを停止する為にもこれを利用する事ができます。ロールバックせずにデータベースを立ち上げる為に
mysqld
処理を停止し、innodb_force_recovery
を 3
に設定し、そして暴走ロールバックを引き起こしているテーブルを
DROP する事ができます。
データベースはそれ以外の場合にゼロ以外の値の
innodb_force_recovery
と共に利用するべきではありません
。innodb_force_recovery
が0よりも大きい場合、安全の為、InnoDB
はユーザがINSERT、UPDATE、または
DELETE 操作を行うのを防ぎます。
InnoDB は 「fuzzy」
チェックポイントとして知られているチェックポイント性能を実装します。InnoDB
は小さいバッチ内のバッファ
プールから変更されたデータベース
ページをフラッシュします。チェックポイント処理の最中にユーザ
SQL
ステートメントの処理を実際に停止させる、バッファ
プールを単一バッチ内でフラッシュする必要はありません。
クラッシュ復旧の最中に、InnoDB
はログ
ファイルに書き込まれたチェックポイント
ラベルを探します。それは、ラベルの前のデータベースへの全ての変更がデータベースのディスク
イメージ内に存在する事を知っています。そして、InnoDB
はデータベースにログされた変更を適用しながら、チェックポイントから前方にログ
ファイルをスキャンします。
InnoDB
は交代制でそのログファイルに書き込みをします。バッファ
プール内のデータベース
ページがディスク上のイメージと異なるようにコミットされた全ての変更は、InnoDB
が復旧を行わなければいけない場合の為にログ
ファイル内で有効である必要があります。これは、InnoDB
がログ
ファイルを再利用し始めた時、ディスク上のデータベースのイメージが、InnoDB
が再利用しようとしているログ
ファイル内にログされた変更を確実に含むという事を意味します。言い換えると、InnoDB
はチェックポイントを作成する必要があり、変更されたデータベース
ページをディスクにフラッシュする事を含んでいる事が多いです。
前出の説明の中で、なぜログ ファイルをとても大きくする事がチェックポイントの中でディスク I/O を救うかも知れないのかが説明されています。ログ ファイル全体の大きさをバッファ プールと同じ、またはそれよりも大きく設定する事は意味を持つ事が多いです。大きいログ ファイルを利用する事の欠点は、データベースに適応させるログされた情報がより多くある為に、クラッシュ復旧に長時間かかるという事です。
Windows 上では InnoDB
はいつもデータベースとテーブル名を小文字で内部的に格納します。データベースを
Unix から Windows に、または Windows から Unix
にバイナリ
フォーマットで移動するには、全てのテーブルとデータベース名を小文字で持つ必要があります。これを行う簡単な方法は、データベースやテーブルを作成する前に
my.cnf や my.ini
ファイルの [mysqld]
セクションに次のラインを追加する事です:
[mysqld] lower_case_table_names=1
MyISAM データ
ファイルのように、InnoDB
データとログ
ファイルは同じ浮動小数点数フォーマットを持つ全てのプラットフォーム上でバイナリ互換性があります。
項13.5.8. 「InnoDB
データベースのバックアップと復旧」
内にリストされている、全ての関連のあるファイルをコピーするだけで
InnoDB
データベースを移動する事ができます。もし浮動小数点フォーマットが異なってても、テーブル内で
FLOAT か DOUBLE
データタイプを利用していなければ、手順は同じです:関連のあるファイルをコピーしてください。もしフォーマットが異なりテーブルが浮動小数点データを含んでいたら、1つのマシン上でテーブルをダンプする為に
mysqldump
を利用し、そして別のマシンにダンプ
ファイルをインポートしなければいけません。
性能を向上させる為のひとつの方法は、インポート トランザクションが生成する大きいロールバック セグメントの為にテーブルスペースが充分な領域を持っていると仮定して、データをインポートする時に自動コミットモードをオフにする事です。テーブル全体か、テーブルのセグメントをインポートした後にコミットを行ってください。
- 13.5.10.1.
InnoDBロック モード - 13.5.10.2.
InnoDBとAUTOCOMMIT - 13.5.10.3.
InnoDBとTRANSACTION ISOLATION LEVEL - 13.5.10.4. 一貫非ロック読み取り
- 13.5.10.5.
SELECT ... FOR UPDATEとSELECT ... LOCK IN SHARE MODEロック読み取り - 13.5.10.6. ネクスト キー ロック:バグの問題を防ぐ
- 13.5.10.7.
InnoDB内での一貫した読み取りの例 - 13.5.10.8.
InnoDB内で各種 SQL ステートメントによって設定されるロック - 13.5.10.9. 暗黙的なトランザクション コミットとロールバック
- 13.5.10.10. デッドロックの検出とロールバック
- 13.5.10.11. デッドロックにどのように対処するか
InnoDB トランザクション
モデル内のゴールは、マルチ バージョン
データベースの優れた性質を、従来の二相ロックと合体させる事です。
InnoDB
は、行レベルでロックを行い、デフォルトではクエリを
Oracle
式の非ロックの一貫した読み取りとして実行します。InnoDB
のロック
テーブルは領域効率の高い方法で格納される為、ロック
エスカレーションは不要です:一般には、複数のユーザがデータベースのあらゆるレコードまたはレコードのランダムなサブセットをロックする事ができ、InnoDB
でメモリ不足が発生する事もありません。
InnoDB
は2つのタイプのロックがあるスタンダード行レベル
ロックを実装します:
共有(
S)ロックはトランザクションが行を読む事を許容します(タプル)。専用(
X)ロックはトランザクションが行を更新、削除する事を許容します。
もしトランザクション T1
が共有(S)ロックをタプル
t 上で保持していたら、
t上のSロックの為のいくつかの独特なトランザクションT2からのリクエストは直ちに認められます。結果として、T1とT2の両方はt上でSロックを保持します。t上のXロックの為のいくつかの独特なトランザクションT2からのリクエストは直ちに認められます。
もしトランザクション T1
が独特な(X)ロックをタプル
t 上で保持していたら、その時は
t
上のロックに対する独特なトランザクション
T2
からのリクエストは直ちに認められません。代わりに、トランザクション
T2 はトランザクション
T1 がタプル t
上でそのロックをリリースするのを待たなければいけません。
さらに、InnoDB はレコード
ロックの共存とテーブル全体のロックを許容する
複数粒度ロック
をサポートします。複数粒度レベルでのロックを実用的にする為に、インテンション
ロック
と呼ばれるロックの追加タイプが利用されます。インテンション
ロックは InnoDB 内のテーブル
ロックです。インテンション
ロックの裏にある考えは、後でトランザクションが、そのテーブル内でどのタイプ(共有か専用か)のロックを行の為に要求するのかを指示するという事です。InnoDB
内で利用されるインテンション
ロックには2つのタイプがあります。(トランザクション
T がテーブル R
上で指示されたタイプのロックをリクエストしたと仮定してください。):
共有インテンション(
IS):トランザクションTはR内の独立行上にSロックを設定する予定です。専用インテンション(
IX):トランザクションTはそれらの行上にXロックを設定する予定です。
インテンション ロック プロトコルは次のようになります:
与えられたトランザクションは与えられた行上で
Sロックを得る前に、まずその行を含んでいるテーブル上にISか、またはさらに強いロックを得る必要があります。与えられたトランザクションは与えられた行上で
Xロックを得る前に、まずその行を含んでいるテーブル上にIXロックを得る必要があります。
これらのルールは ロック タイプ変換互換性マトリックス を用いて便利に要約する事ができます:
| ? | X | IX | S | IS |
X | 対立 | 対立 | 対立 | 対立 |
IX | 対立 | 互換性あり | 対立 | 互換性あり |
S | 対立 | 対立 | 互換性あり | 互換性あり |
IS | 対立 | 互換性あり | 互換性あり | 互換性あり |
既存ロックと互換性があれば、リクエストしているトランザクションにロックが与えられます。既存ロックと対立すれば、リクエストしているトランザクションにロックは与えられません。トランザクションは、既存の対立中のロックがリリースされるまで待ちます。もしロックのリクエストが既存ロックと対立する為にデッドロックが起り、そのロックが与えられないとしたら、エラーが発生します。
従って、インテンション ロックはフル
テーブル
リクエスト以外は何もブロックしません。(例えば
LOCK TABLES ...
WRITE)IX と
IS
ロックの主な目的は、誰かが行をロックしている、またはテーブル内の行をロックしようとしている、という事です。
次の例は、ロック リクエストがデッドロックを引き起こす時にどのようにエラーが発生するかを表しています。この例には、A と B の2つのクライアントが登場します。
最初に、クライアント A
が行を1つ含むテーブルを作成し、トランザクションを開始します。トランザクション内で、A
は共有モードで選択した行に
S ロックを獲得します:
mysql>CREATE TABLE t (i INT) ENGINE = InnoDB;Query OK, 0 rows affected (1.07 sec) mysql>INSERT INTO t (i) VALUES(1);Query OK, 1 row affected (0.09 sec) mysql>START TRANSACTION;Query OK, 0 rows affected (0.00 sec) mysql>SELECT * FROM t WHERE i = 1 LOCK IN SHARE MODE;+------+ | i | +------+ | 1 | +------+ 1 row in set (0.10 sec)
次に、クライアント B がトランザクションを開始し、テーブルから行を削除しようとします:
mysql>START TRANSACTION;Query OK, 0 rows affected (0.00 sec) mysql>DELETE FROM t WHERE i = 1;
削除作業は X
ロックを必要とします。クライアント A
が保持している S
ロックと互換性が無い為にそのロックは与えられず、そのリクエストは行とクライアント
B のロック リクエストの列に並びます。
最後に、クライアント A もテーブルから行を削除しようとします:
mysql> DELETE FROM t WHERE i = 1;
ERROR 1213 (40001): Deadlock found when trying to get lock;
try restarting transaction
クライアント A は行を削除する為に
X
ロックが必要なので、ここでデッドロックが発生します。しかし、クライアント
B が既に X
ロックへのリクエストを持ち、またその
S ロックをクライアント A
がリリースするのを待っている為に、ロック
リクエストは与えられません。B による
X
ロックのリクエストの為に、A
によって保持されている S
ロックをX
ロックにアップグレードするる事もできません。結果として、InnoDB
はクライアント A
に対してエラーを生成し、そのロックをリリースします。その時点で、クライアント
B のロック リクエストが与えられ、B
はテーブルから行を削除します。
InnoDB
内では、全てのユーザ行動はトランザクション内で起こります。もし自動コミット
モードが有効なら、各 SQL
ステートメントはそれ自体の上に単一トランザクションを形作ります。MySQL
はデフォルトで自動コミットを有効にして新しい接続を始めます。
もし自動コミット モードが SET AUTOCOMMIT =
0
を利用してオフにされたら、ユーザは常にトランザクションを開いていると考える事ができます。SQL
COMMIT か ROLLBACK
ステートメントは現在のトランザクションを終了し新しい物を開始します。COMMIT
は、現在のトランザクション内で行われた変更は永続的であり、別のユーザからも見る事ができるという事を意味します。ROLLBACK
ステートメントは反対に、現在のトランザクションによって行われた全ての変更をキャンセルします。両ステートメントは、現在のトランザクションの最中に設定された全ての
InnoDB ロックをリリースします。
もしその接続の自動コミットが有効であれば、ユーザは明示的な
START TRANSACTION か
BEGIN
ステートメントを利用して複合ステートメント
トランザクションを開始する事でそれを実行し、また
COMMIT か ROLLBACK
を利用して終了する事ができます。
SQL:1992
トランザクション分離レベルの観点では、InnoDB
デフォルトは REPEATABLE READ
です。InnoDB は SQL
スタンダードによって説明されている4つの全てのトランザクション分離レベルを提供します。コマンド
ライン上、またはオプション ファイル内で
--transaction-isolation
オプションを利用する事で、全ての接続にデフォルトの分離レベルを設定する事ができます。例えば、オプション
ファイルの [mysqld]
セクション内で次のようにオプションを設定する事ができます:
[mysqld]
transaction-isolation = {READ-UNCOMMITTED | READ-COMMITTED
| REPEATABLE-READ | SERIALIZABLE}
ユーザは SET TRANSACTION
ステートメントを利用して単一セッションや全ての新しい接続の分離レベルを変更する事ができます。その構文は次のようになります:
SET [SESSION | GLOBAL] TRANSACTION ISOLATION LEVEL
{READ UNCOMMITTED | READ COMMITTED
| REPEATABLE READ | SERIALIZABLE}
--transaction-isolation
オプションのレベル名内にはハイフンがありますが、SET
TRANSACTION
ステートメントには無い事に注意してください。
デフォルト動作は、次の(まだ始まっていない)トランザクションの分離レベルを設定する事です。もし
GLOBAL
キーワードを利用すると、そのステートメントはその時点以降に作成された全ての新しい接続に対して、デフォルトのトランザクション
レベルをグローバルに設定します。(既に存在する接続には設定しません。)これには
SUPER
権限が必要です。SESSION
キーワードの利用は、現在の接続上で今後行われる全てのトランザクションに対して、デフォルト
トランザクション レベルを設定します。
全てのクライアントは自由にセッションの分離レベル(トランザクションの最中だとしても)、または次のトランザクションの分離レベルを変更する事ができます。
次のステートメントを利用して
tx_isolation
システム変数の値を確認する事で、グローバル、またセッション
トランザクションの分離レベルを決定する事ができます:
SELECT @@global.tx_isolation; SELECT @@tx_isolation;
行レベル ロック内では、InnoDB
はネクスト キー
ロックを利用します。これは、インデックス
レコード以外に、InnoDB
が、別のユーザによってインデックス
レコードの直前に挿入される事を防ぐ為に、インデックス
レコードに先行する 「ギャップ」
をロックする事もできるという事を意味します。ネクスト
キー ロックは、インデックス
レコードとその前のギャップをロックするロックを参照します。ギャップ
ロックは、ただ単に、いくつかのインデックス
レコードの前にギャップをロックするだけのロックを参照します。
InnoDB
内の各分離レベルに関する詳細説明は次の物です:
READ UNCOMMITTEDSELECTステートメントは非ロックの方法で実行されますが、レコードの以前のバージョンが利用される事もあるでしょう。従って、この分離レベルを利用したこのような読み込みは一貫性がありません。これは 「ダーティ リード」 とも呼ばれます。そうでなければ、この分離レベルはREAD COMMITTEDのように機能します。READ COMMITTED若干 Oracle に似ている分離レベル。全ての
SELECT ... FOR UPDATEとSELECT ... LOCK IN SHARE MODEステートメントは、インデックス レコードだけをロックしそれらの前のギャップはロックしませんので、ロックされたレコードの隣に新しいレコードの自由挿入を許容します。 固有検索条件を持つ固有インデックスを利用したUPDATEとDELETEステートメントは、検出されたインデックス レコードだけをロックし、その前のギャップはロックしません。 値域タイプのUPDATEとDELETEステートメント内では、InnoDBはネクスト キーかギャップ ロックを設定し、別のユーザからの値域によって変換されたギャップへの挿入をブロックする必要があります。これは、「phantom rows」 が MySQL 複製と復旧が機能する為にブロックされなければいけない為必要になります。一貫した読み取りは、Oracle 内と同じように機能します:同じトランザクション内でも、各一貫した読み取りはそれ自体の新鮮なスナップショットを設定し、読み取ります。詳しくは 項13.5.10.4. 「一貫非ロック読み取り」 を参照してください。
REPEATABLE READこれは
InnoDBのデフォルト分離レベルです。固有検索条件を持つ固有インデックスを利用するSELECT ... FOR UPDATE、SELECT ... LOCK IN SHARE MODE、UPDATE、そしてDELETEステートメントは、前にあるギャップではなく、検索したインデックス レコードのみをロックします。その他の検索条件を利用して、これらの操作はネクスト キーかギャップ ロックでインデックス範囲をスキャンしながらネクスト キー ロックを採用し、別のユーザによる新しい挿入をブロックします。一貫した読み取りの中に、
READ COMMITTED分離レベルとの重要な違いがあります:同一トランザクション内の全ての一貫した読み取りは、最初の読み取りで確立された同じスナップショットを読み取ります。このしきたりは、もし同じトランザクション内でいくつかの単純なSELECTステートメントを発行すると、これらのSELECTステートメントはお互いに対しても一貫性を持つという事を意味します。詳しくは 項13.5.10.4. 「一貫非ロック読み取り」 を参照してください。SERIALIZABLEこのレベルは
REPEATABLE READと似ていますが、InnoDBは暗黙的に全ての単純なSELECTステートメントをSELECT ... LOCK IN SHARE MODEにコミットします。
一貫した読み取りとは、InnoDBがそのマルチ
バージョニング機能を使用して、ある時点でのデータベースのスナップショットをクエリに提示する事を意味します。クエリには、その時点より前にコミットされたトランザクションによる変更のみが示され、その時点より後のトランザクションまたはコミットされていないトランザクションによる変更は示されません。例外として、クエリを発行したトランザクション自体による変更はクエリに示されます。
このルールに対する例外によって次のような事が起こると覚えておいてください:テーブル内のいくつかの行を更新すると、SELECT
は他の行の古いバージョンを確認すると同時に、更新された行の最新のバージョンを確認します。もし別のユーザが同時に同じテーブルを更新すると、今までとは違う状態のテーブルをデータベース内で確認するかもしれないいう例外があるかもしれません。
デフォルトの REPEATABLE READ
分離レベルで起動しているなら、同じトランザクション内の全ての一貫した読み取りは、そのトランザクション内の最初の読み取りで確立されたスナップショットを読み取ります。
現在のトランザクションをコミットしその後新しいクエリを発行する事で、クエリにより新鮮なスナップショットを得る事ができます。
InnoDB が READ COMMITTED
と REPEATABLE READ 分離レベル内で
SELECT
ステートメントを処理する中で、一貫した読み取りはデフォルトのモードです。一貫した読み取りはそれがアクセスするテーブル上に一切ロックを設定しないので、別のユーザは、そのテーブル上で一貫した読み取りが行われているのと同時にそれらのテーブルを自由に変更する事ができます。
一貫した読み取りは DROP TABLE と
ALTER TABLE
全体には機能しない事に注意してください。MySQL
がドロップされたテーブルを利用する事ができず、InnoDB
がそのテーブルを破壊する為、一貫した読み取りは
DROP TABLE
全体には機能しません。ALTER TABLE
は元テーブルのテンポラリ
コピーを作成し、それができた時に元テーブルを破壊する事で機能する為、一貫した読み取りは
ALTER TABLE
全体には機能しません。トランザクション内で一貫した読み取りを再発行する時、新しいテーブル内の行はトランザクションのスナップショットが撮られた時に存在していなかった為に見る事ができません。
場合によっては、一貫した読み取りは便利ではありません。例えば、テーブル
child
に新しい行を追加したければ、子供がテーブル
parent
に親を持っている事を確認するでしょう。次の例は、応用コード内でどのように参照整合性を実装するのかを表しています。
テーブル parent
を読み取る為に一貫した読み取りを利用し、実際にテーブル内に子供の親を確認したと仮定してください。テーブル
child
に子供行を安全に追加する事ができますか?別のユーザが知らない間にテーブル
parent
から親行を削除する可能性があるので、答えはノーです。
この解決法は、LOCK IN SHARE MODE
を利用して SELECT をロック
モードで実行する事です:
SELECT * FROM parent WHERE NAME = 'Jones' LOCK IN SHARE MODE;
共有モードで読み取りを行うというのは、まず最新の有効なデータを読み取り、そして読んだ行に共有モードを設定するという意味です。共有モード
ロックは、読み取った行が別の人によって更新されたり、削除されたりする事を防ぎます。また、もし最新データが別のクライアント接続のコミットされていないトランザクションに属していたら、そのトランザクションがコミットされるまで待ちます。先行クエリが親
'Jones'
を返すのを確認した後、child
テーブルに子レコードを安全に追加し、トランザクションをコミットする事ができます。
別の例を見てみましょう:テーブル
child
に追加された各子供に固有識別子を割り当てる為に利用する整数カウンタ
フィールドが、テーブル child_codes
内にあります。カウンタの現在値を読む為に、一貫した読み取りや、共有モード読み取りを利用する事は、そのデータベースの2ユーザが同じカウンタ値を確認する可能性があり、またその2ユーザが同じ識別子を利用してテーブルに子供を追加しようとすると複製キーエラーが発生する為、良い考えとは言えません。
もし2ユーザがカウンタを同時に読むと、少なくても1ユーザはカウンタを更新しようとする時にデッドロックになってしまう為、
LOCK IN SHARE MODE
はこの場合良い解決法とはいえません。
この場合、カウンタの読み取りとインクリメントを実装する為の良い方法が2つあります:(1)
カウンタを1でインクリメントする事で更新し、その後にだけ読み取る、または、
(2) ロックモード FOR UPDATE
を利用してまずカウンタを読み取り、その後にインクリメントする。後者の方法は、次のように実装できます:
SELECT counter_field FROM child_codes FOR UPDATE; UPDATE child_codes SET counter_field = counter_field + 1;
A SELECT ... FOR UPDATE
は、読み取る各行上に専用ロックを設定し、最新の有効データを読み取ります。従って、それは
SQL UPDATE
が行上に設定する物と同じロックを設定します。
前出の例は、ただ単に SELECT ... FOR
UPDATE
がどのように機能するかを表す例です。MySQL
内では、固有識別子を生成する特定のタスクは、実際にはテーブルへの単一アクセスの利用だけで達成する事ができます:
UPDATE child_codes SET counter_field = LAST_INSERT_ID(counter_field + 1); SELECT LAST_INSERT_ID();
SELECT
ステートメントはただ単に識別子情報を検索するだけです。(現在の接続特有の物)これはテーブルにアクセスしません。
IN SHARE MODE と FOR
UPDATE
読み取りによって設定されたロックは、トランザクションがコミットされたりロールバックされたりした時にリリースされます。
行レベル ロック内では、InnoDB は
ネクスト キー ロック
と呼ばれるアルゴリズムを利用します。InnoDB
は、それがテーブルのインデックスを検索やスキャンする時に、遭遇したインデックス
レコード上で共有、または専用ロックを設定する、という方法で行レベル
ロックを実行します。従って、行レベル
ロックは実際はインデックス レコード
ロックであるという事になります。
InnoDB がインデックス
レコード上で設定するロックは、そのインデックス
レコードの前の 「ギャップ」
にも影響を与えます。もしユーザがインデックス内のレコード
R
上に共有または専用ロックを持っていたら、別のユーザはインデックスの順番で
R の直前に新しいインデックス
レコードを挿入する事はできません。このようなギャップのロックは、一般的に
「バグの問題」
と呼ばれる物を防ぐ為に行われます。後で選択した行内のいくつかのカラムを更新するつもりで、100よりも大きい値の識別子を持つ
child
テーブルから全ての子供を読み、ロックしたいと仮定します:
SELECT * FROM child WHERE id > 100 FOR UPDATE;
id
カラム上にインデックスがあると仮定してください。クエリは、id
が100以上の最初のレコードから、そのインデックスをスキャンします。もしインデックス
レコード上に設定されたロックがギャップに挿入された物をロックしなければ、その一方で新しい行がテーブルに挿入されるでしょう。
もし同じトランザクション内で同じ
SELECT
を実行すると、クエリから返された結果セット内に新しい行を見つける事ができます。これは、トランザクションの分離原理に反しています:トランザクションは、読み取ったデータをトランザクションの最中に変更させない為に起動する必要があります。行セットをデータ項目であるとみなすと、新しい
「バグ」
の子供はこの分離原理に違反します。
When InnoDB
がインデックスをスキャンする時、インデックス内の最後のレコードの後のギャップをロックする事もできます。それは前出の例の中で起きています:InnoDB
によって設定されるロックは、id
が100以上になるテーブルへの挿入を防ぎます。
アプリケーション内に一意性チェックを実装する為にネクスト キー ロックを利用する事ができます:共有モードでデータを読み取り、挿入しようとする行に重複が見られなければ、行を確実に挿入できます。また、読み取り中は対象となる行の後続の行にネクスト キー ロックが設定されて、第三者による重複行の挿入を防ぎます。このように、ネクスト キー ロックによって、テーブル内に存在しない物を 「ロック」 する事ができます。
デフォルトの REPEATABLE READ
分離レベルで起動していると仮定して下さい。一貫した読み取り(通常の
SELECT
ステートメント)では、InnoDBは、クエリがデータベースを参照する時の基準となるタイムポイントをトランザクションに与えます。こうして、タイムポイントが割り当てられた後に、他のトランザクションが行を削除してコミットしたとしても、一度読み取った内容は変わりません。挿入と更新も同じように扱われます。
割り当てられたタイムポイントを先に進めるには、トランザクションをコミットし、新たな
SELECT を実行します。
これは、マルチ バージョン並行処理制御 と呼ばれています。
User A User B
SET AUTOCOMMIT=0; SET AUTOCOMMIT=0;
time
| SELECT * FROM t;
| empty set
| INSERT INTO t VALUES (1, 2);
|
v SELECT * FROM t;
empty set
COMMIT;
SELECT * FROM t;
empty set
COMMIT;
SELECT * FROM t;
---------------------
| 1 | 2 |
---------------------
1 row in set
この例の中では、ユーザ A は、ユーザ A と B の両方が挿入をコミットした時だけ、B によって挿入された行を確認する事ができ、それによってタイムポイントは B のコミットよりも先に進みます。
データベースの 「最新の」
状態を確認したければ、READ
COMMITTED
分離レベルかロック読み取りのどちらかを利用しなければいけません:
SELECT * FROM t LOCK IN SHARE MODE;
ロックする読み取り、UPDATE、または
DELETE は通常、SQL
ステートメントの処理の中でスキャンされる全てのインデックス
レコード上にレコード
ロックを設定します。行を排除するステートメント内に
WHERE
条件があればそれは問題ではありません。InnoDB
は正確な WHERE
条件を記憶しませんが、どのインデックス範囲がスキャンされたのかは分かっています。レコード
ロックは通常、レコードの前に
「ギャップ」
への挿入も速やかにブロックするネクスト キー
ロックです。
もし設定されるロックが専用であれば、InnoDB
は常にクラスタ化されたインデックス
レコードの検索と、それに対するロックの設定もします。
もしご自分のステートメントに適応したインデックスがなく、MySQL がステートメントを処理する為にテーブル全体をスキャンしなければいけないなら、テーブルの全ての行がロックされ、それはその代わりにテーブルへの別のユーザによる全ての挿入をブロックします。クエリが不必要にたくさんの行をスキャンする必要がなくなるように、よいインデックスを作成する事が重要です。
InnoDB は次のように特定のロック
タイプを設定します:
SELECT ... FROMは一貫した読み取りであり、データベースのスナップショットを読み取り、トランザクションの分離レベルがSERIALIZABLEに設定されなければロックは設定しません。これは、SERIALIZABLEレベルに対して、直面するインデックス レコード上に共有ネクスト キー ロックを設定します。SELECT ... FROM ... LOCK IN SHARE MODEは、その読み取りが直面する全てのインデックス レコード上に共有ネクスト キー ロックを設定します。SELECT ... FROM ... FOR UPDATEは、その読み取りが直面する全てのインデックス レコード上に専用共有ネクスト キー ロックを設定します。INSERT INTO ... VALUES (...)は挿入された行上に専用ロックを設定します。このロックはネクスト キー ロックではなく、挿入された行の前のギャップに別のユーザが挿入する事を防ぎます。もし複製キー エラーが発生すると、複製インデックス レコード上の共有ロックが設定されます。テーブル上であらかじめ指定された
AUTO_INCREMENTカラムを初期化している間、InnoDBはAUTO_INCREMENTカラムと関係しているインデックスの最後に専用ロックを設定します。自動インクリメント カウンタにアクセスする時、
InnoDBは、トランザクション全体の最後までではなく、現在の SQL ステートメントの最後まで続く、特別なテーブル ロック モードAUTO-INCを利用します。AUTO-INCテーブル ロックが行われている間は、別のクライアントはテーブルに挿入ができない事に注意してください。 項13.5.10.2. 「InnoDBとAUTOCOMMIT」 を参照してください。InnoDBは、ロックを設定せずに、あらかじめ初期化されたAUTO_INCREMENTカラムの値をフェッチします。INSERT INTO T SELECT ... FROM S WHERE ...はTに挿入された各行上に専用(ネクスト キーではない)ロックを設定します。InnoDBは、innodb_locks_unsafe_for_binlogが有効でなければ共有ネクスト キー ロックをSに設定し、その場合それはSに対して一貫した読み取りとしての検索を行います。InnoDBは後者の場合にロックを設定する必要があります:バックアップからの前進復旧では、全ての SQL ステートメントはそれが元々行われたのと全く同じ方法で実行されなければいけません。CREATE TABLE ... SELECT ...は、前出の項目のように、SELECTを一貫した読み取りとして、または共有ロックを利用して実行します。REPLACEは、もし固有キーにコリジョンがなければ挿入と同じように行われます。反対に、専用ネクスト キー ロックは更新されなければいけない行上に置かれます。UPDATE ... WHERE ...は、検索が直面する全てのレコード上に専用ネクスト キー ロックを設定します。DELETE FROM ... WHERE ...は、検索が直面する全てのレコード上に専用ネクスト キー ロックを設定します。もし
FOREIGN KEY制約がテーブル上で定義されると、確認される制約条件を要求する全ての挿入、更新、または削除が、制約を確認する為に参照するレコード上に共有レコード レベル ロックを設定します。InnoDBも、制約が失敗する場合に備えてこれらのロックを設定します。LOCK TABLESはテーブル ロックを設定しますが、これはこれらのロックを設定するInnoDBレイヤより上位の MySQL レイヤです。InnoDBはinnodb_table_locks=1(デフォルト)とAUTOCOMMIT=0であればテーブル ロックを認識しており、またInnoDBより上位の MySQL レイヤは行レベル ロックを識別します。そうでなければ、InnoDBの自動デッドロック検出は、そのようなテーブル ロックが関連しているデッドロックを検出する事はできません。 また、上位の MySQL レイヤは行レベル ロックを識別しないので、別のユーザが現在行レベル ロックを持っているテーブル上にテーブル ロックを得る事が可能です。しかし、項13.5.10.10. 「デッドロックの検出とロールバック」 で説明されているように、これはトランザクション インテグリティを危険にさらしたりはしません。項13.5.16. 「InnoDBテーブル上の制約」 もご参照ください。
デフォルトにより、MySQL は自動コミット
モードが有効な状態で各クライアント接続を起動します。自動コミットが有効な時、もしステートメントがエラーを返さなければ
MySQL は各 SQL
ステートメントの後にコミットを行います。もし
SQL
ステートメントがエラーを返したら、コミットやロールバック性能はそのエラーによって決まります。詳しくは
項13.5.15. 「InnoDB エラー処理」
を参照してください。
もし自動コミット モードがオフで、最後のトランザクションを明示的にコミットせずに接続を閉じると、MySQL はそのトランザクションをロールバックします。
次の各ステートメント(そしてそれらの同義語)は、まるでステートメントを実行する前に
COMMIT
を行ったかのように、暗黙にトランザクションを終了します。
ALTER FUNCTION、ALTER PROCEDURE、ALTER TABLE、BEGIN、CREATE DATABASE、CREATE FUNCTION、CREATE INDEX、CREATE PROCEDURE、CREATE TABLE、DROP DATABASE、DROP FUNCTION、DROP INDEX、DROP PROCEDURE、DROP TABLE、LOAD DATA INFILELOCK TABLES、RENAME TABLE、SET AUTOCOMMIT=1、START TRANSACTION、TRUNCATE TABLE、UNLOCK TABLESMySQL 5.1.3 から、
ALTER VIEW、CREATE TRIGGER、CREATE USER、CREATE VIEW、DROP TRIGGER、DROP USER、DROP VIEW、そしてRENAME USERステートメントは暗黙的なコミットを引き起こすようになりました。UNLOCK TABLESは、もしテーブルが現在LOCK TABLESでロックされていたらトランザクションを行います。これは、FLUSH TABLES WITH READ LOCKステートメントがテーブル レベル ロックを取得しない為、これに続くUNLOCK TABLESに対しては行われません。InnoDB内のCREATE TABLEステートメントは単一トランザクションとして生成されます。これは、ユーザからのROLLBACKはトランザクションの最中にユーザが作成したCREATE TABLEステートメントを解除しないという意味です。CREATE TABLEとDROP TABLEは、もしTEMPORARYキーワードが利用されたらトランザクションを実行しません。(これは、コミットを引き起こさないCREATE INDEXのようなテンポラリ テーブルへのその他の操作には当てはまりません。)MySQL 5.1.11 以前では、
LOAD DATA INFILEは全てのストレージ エンジンに対して暗黙的なコミットを引き起こしました。MySQL 5.1.12 からは、NDBストレージエンジンを利用しているテーブルに対してだけ暗黙的なコミットを引き起こすようになりました。更なる情報については、バグ #11151を参照してください。
トランザクションはネスト化されません。これは、START
TRANSACTION
ステートメントかその同義語の1つを発行する時点でのトランザクションに対して実行される、暗黙的な
COMMIT の結果です。
トランザクションが ACTIVE
状態の間は、暗黙的なコミットを引き起こすステートメントは
XA
トランザクションでは利用する事はできません。
InnoDB
は自動的にトランザクションのデッドロックを検出し、デッドロックを破壊する為にトランザクションをロールバックします。InnoDB
は、トランザクションのサイズが挿入、更新、または削除された行数によって決定される小さいトランザクションを選んでロールバックしようとします。
InnoDB は
innodb_table_locks=1 (デフォルト)と
AUTOCOMMIT=0 であればテーブル
ロックを認識しており、またそれより上位の
MySQL レイヤは行レベル
ロックを識別します。そうでなければ、InnoDB
は MySQL LOCK TABLES
ステートメントによるテーブル ロック
セットや InnoDB 以外のストレージ
エンジンによるロック
セットが関連しているデッドロックを検出する事ができません。innodb_lock_wait_timeout
システム変数の値を設定する事によって、これらの状況を解決しなければいけません。
InnoDB
がトランザクションの完全なロールバックを実行する時、トランザクションによって設定される全てのロックはリリースされます。しかし、もし単一
SQL
ステートメントだけがエラーの結果ロールバックされると、ステートメントによって設定されたいくつかのロックは維持されるかもしれません。これは、InnoDB
が、後でどの行がどのステートメントによって設定されたのかという事を確認する事ができないようなフォーマットで行ロックを格納する為に起こります。
デッドロックはトランザクション データベースの中ではよく知られている問題ですが、ある特定のトランザクションを全く起動できないほど頻繁に起きる訳ではないのならば危険では有りません。 通常は、トランザクションがデッドロックの為にロールバックされたらそれを再発行できる準備が常にできているように、アプリケーションを書き込まなければいけません。
InnoDB は自動行レベル
ロックを利用します。単一行を挿入または削除したばかりのトランザクションの場合でもデッドロックを得る事ができます。これは、これらの操作は実際は
「アトミック」
ではないからです。それらは自動的に挿入または削除された行の(可能であればいくつかの)インデックス
レコード上にロックを設定します。
次のテクニックを利用して、デッドロックに対処し、それらの発生の可能性を減らす事ができます:
SHOW ENGINE INNODB STATUSを利用して最新のデッドロックの原因を究明してください。それで、アプリケーションがデッドロックを防ぐ様に調整する事ができます。トランザクションがデッドロックのせいで失敗したら再発行できるように常に準備しておいてください。デッドロックは危険ではありません。もう一度やってみてください。
トランザクションを頻繁にコミットしてください。小さいトランザクションはコリジョンの傾向が少ないです。
もしロック読み取り(
SELECT ... FOR UPDATEor... LOCK IN SHARE MODE)を利用しているなら、READ COMMITTEDのような低分離レベルを利用するように試みてください。決まった順番でテーブルと行にアクセスしてください。するとトランザクションは明確な列になりデッドロックしません。
テーブルに適切なインデックスを追加してください。するとクエリがスキャンしなければいけないインデックス レコードが減り、その結果ロックの設定が減ります。MySQL サーバが、クエリにとってどのインデックスが最適だと認識するのかを究明する為に
EXPLAIN SELECTを利用してください。ロックの利用を少なくしてください。もし
SELECTが古いスナップショットからデータを返す事を許容できるなら、それに条項FOR UPDATEかLOCK IN SHARE MODEを追加しないでください。同じトランザクション内のそれぞれの一貫した読み取りは、それ自体の新鮮なスナップショットから読み取りをするので、READ COMMITTED分離レベルを利用する事は良い事です。もし他に方法がなければ、テーブル レベル ロックを利用してトランザクションを直列化してください。
LOCK TABLESをInnoDBテーブルのようなトランザクション テーブルと共に利用する正しい方法は、AUTOCOMMIT = 0を設定し、トランザクションを明示的にコミットするまではUNLOCK TABLESをコールしないという方法です。例えば、もしテーブルt1に書き込み、テーブルt2から読み取る必要があれば、これを行う事ができます:SET AUTOCOMMIT=0; LOCK TABLES t1 WRITE, t2 READ, ...;
... do something with tables t1 and t2 here ...COMMIT; UNLOCK TABLES;テーブル
child_codes内にテーブル レベル ロックはトランザクションの列を整え、デッドロックを防ぎます。トランザクションを直列化する別の方法は、単一行だけを含む補助 「セマフォ」 テーブルを作成する事です。各トランザクションが別のテーブルにアクセスする前にその行を更新させてください。そうすると、全てのトランザクションは連続で起こります。直列化ロックは行レベル ロックなので、
InnoDBインスタント デッドロック検出アルゴリズムもこの場合機能するという事に注意してください。MySQL テーブル レベル ロックでは、デッドロックを解決する為にタイムアウト法を利用しなければいけません。LOCK TABLESコマンドを利用するアプリケーション内では、AUTOCOMMIT=1であれば MySQL はInnoDBデーブル ロックを設定しません。
InnoDB内では、長いPRIMARY KEYを持つと、その値が全てのセカンダリ インデックス レコードを利用して格納される為、ディスク領域の無駄遣いになります。(詳しくは 項13.5.13. 「InnoDBテーブルとインデックス構造」 をご確認ください。)もし主キーが長かったら、AUTO_INCREMENTカラムを主キーとして作成してください。もし Unix
topツールか、Windows タスク マネージャが、作業負荷 CPU 使用率が 70% 以下であると表示したら、その作業負荷はおそらくディスクに頼っているでしょう。 トランザクション コミットをたくさん作りすぎているか、バッファ プールが小さすぎるという事でしょう。バッファプールを大きく作成する事も良いですが、物質的メモリの 80% 以上に設定しないでください。複数の変更を1つのトランザクションにまとめてください。
InnoDBは、もしトランザクションがデータベースに変更を行うなら、各トランザクション コミットの際にディスクにログをフラッシュしなければいけません。もしディスクが OS を 「欺かなければ」、ディスクの回転速度は一般的に最大167 回転/秒で、コミット数も1秒につき167th に制限されます。クラッシュが発生した時にいくつかの最新のコミットされたトランザクションの損失を受け入れる事ができるなら、
innodb_flush_log_at_trx_commitパラメータを0に設定する事ができます。フラッシュが保証されていなくても、InnoDBは1秒に1回ログをフラッシュします。バッファ プールと同じ大きさまでログ ファイルを大きくしてください。
InnoDBがログ ファイルを一杯に書き込むと、それはチェックポイント内でバッファ プールの変更された内容をディスクに書き込まなければいけません。小さいログ ファイルは多くの不必要なディスク書き込みを引き起こします。大きいログ ファイルの欠点は、復旧時間が長いという事です。ログ バッファもとても長く作成してください。(約 8MB)
もし可変長文字列を格納していたり、カラムが
NULL値をたくさん含んでいたら、CHARの代わりにVARCHARデータ タイプを利用してください。CHAR(カラムは文字列が短かったりその値がN)NULLだとしても、データを格納する為にいつもN文字を取ります。小さいテーブルはバッファ プール内によりフィットし、ディスク I/O を減らします。row_format=compact(MySQL 5.1 内のデフォルトInnoDBレコードフォーマット) と、utf8やsjisのような可変長文字セットを利用する時、CHAR(は最低でもN)Nバイト分の変数量領域を占有します。GNU/Linux と Unix のいくつかのバージョンでは、Unix
fsync()コール(InnoDBがデフォルトで利用する物)を利用してファイルをディスクにフラッシュする方法やそれと似た方法は、スピードが大変遅いです。もしデータベースの書込み性能に満足していなければ、O_DSYNCにinnodb_flush_methodパラメータを設定してみるのが良いかもしれません。ほとんどのシステム上でO_DSYNCのスピードは遅いかもしれませんが、お使いの物はそうではないかもしれません。InnoDBストレージ エンジンを x86_64 アーキテクチャ(AMD Opteron)の Solaris 10で利用する時、forcedirectioオプションを利用して、InnoDBに関連するファイルを格納するのに利用されるファイル システムをマウントする事が重要です。(Solaris 10/x86_64 のデフォルトはこのオプションを利用 しません。)forcedirectio利用に失敗すると、このプラットフォーム上でのInnoDBのスピードと性能の深刻な劣化を引き起こします。Solaris 2.6 以降のリリース版と全てのプラットフォーム(sparc/x86/x64/amd64)で、大きい
innodb_buffer_pool_size値と共にInnoDBストレージ エンジンを利用する時、未加工デバイスや別々のディレクト I/O UFS ファイル システム(マウント オプションforcedirectioを利用。mount_ufs(1M)を参照)上にInnoDBデータ ファイルとログ ファイルを置く事で、大幅な性能向上を実現する事ができます。Veritas ファイル システム VxFS ユーザは、マウント オプションconvosync=directを利用しなければいけません。MyISAMテーブルに対する物などのようなその他 MySQL データ ファイルはディレクト I/O ファイル システム上に置くべきではありません。実行ファイルやライブラリは、ディレクト I/O ファイル システム上に置いては いけません。InnoDBにデータをインポートする時、MySQL が自動コミットを持っていると各挿入ごとにディスクへのログ フラッシュが要求されるので、自動コミットを持っていない事を確認して下さい。インポート操作の最中に自動コミットを無効にするには、それをSET AUTOCOMMITとCOMMITステートメントで囲んで下さい:SET AUTOCOMMIT=0;
... SQL import statements ...COMMIT;もし mysqldump オプション
--optを利用すれば、SET AUTOCOMMITとCOMMITステートメントで囲まなくてもInnoDBテーブル内にすばやくインポートできるダンプ ファイルを得る事ができます。大量挿入の大きいロールバックに気をつけてください:
InnoDBは挿入時にディスク I/O を節約する為に挿入バッファを利用しますが、対応するロールバック内ではそのような仕組みは利用されません。ディスクに頼ったロールバックを実行するには、それと対応する挿入操作の30倍の時間がかかります。データベース処理を停止しても、ロールバックはサーバ起動の際にもう一度起動するので意味がありません。暴走ロールバックを無くす唯一の方法は、ロールバックが CPU に頼り処理が速くなるようにバッファ プールを増やす事、または特別な方法を利用する事です。詳しくは 項13.5.8.1. 「InnoDB復旧の強制」 を参照してください。その他のディスクに頼った大きい操作にも気をつけてください。テーブルを空にするには
DROP TABLEとCREATE TABLEを利用し、DELETE FROMは利用しないでください。tbl_nameもし行をたくさん挿入したいのであれば、クライアントとサーバ間の伝達オーバーヘッドを減らす為に 複数行
INSERT構文を利用してください:INSERT INTO yourtable VALUES (1,2), (5,5), ...;
この方法は、
InnoDBテーブルだけではなく、全てのテーブルへの挿入に有効なヒントです。もし2番目のキー上に
UNIQUE制限があったら、インポート操作の最中に一時的に一意性チェックを切り、テーブル インポートのスピードを上げる事ができます:SET UNIQUE_CHECKS=0;
... import operation ...SET UNIQUE_CHECKS=1;大きいテーブルに対しては、
InnoDBが2番目のインデックス レコードをバッチ内に書く為にそれ自身の挿入バッファを利用する事ができるので、この作業をするとディスク I/O を大幅に節約する事ができます。データが複製キーを含んでいない事を必ず確認してください。UNIQUE_CHECKSはストレージエンジンが複製キーを無視する事を許可しますが、それを要求はしません。もしテーブル内に
FOREIGN KEY制約があったら、インポート セッションの持続時間に対して外部キー チェックを切る事でテーブル インポートのスピードを早める事ができます:SET FOREIGN_KEY_CHECKS=0;
... import operation ...SET FOREIGN_KEY_CHECKS=1;大きいテーブルに対しては、これでディスク I/O を大幅に節約する事ができます。
もし頻繁には更新されないテーブルに自動更新クエリを持っていたら、次のクエリ キャッシュを利用してください:
[mysqld] query_cache_type = ON query_cache_size = 10M
MyISAMとは違い、InnoDBはそのテーブル内にインデックス濃度を格納しません。代わりに、InnoDBは、起動してから初めてアクセスするテーブルに対して自動更新を算出します。多数のテーブルがあると、この操作はかなり時間がかかります。重要なのは初期テーブル起動操作なので、後ほど利用する時に備えてテーブルを 「暖める」 為に、SELECT 1 FROMのようなステートメントを発行する事で起動後に速やかにこれを利用した方が良いでしょう。tbl_nameLIMIT 1
MySQL Enterprise ご自分専用の特定の環境に適応する最適化推奨案の為に、MySQL ネットワーク モニタリングとアドバイス サービスの購読をお勧めします。追加情報については http://www-jp.mysql.com/products/enterprise/advisors.html を参照してください。
InnoDB は InnoDB
内部の状態についての情報をプリントする
InnoDB
モニタを含んでいます。ご自分の SQL
クライアントにスタンダード
InnoDB
モニタのアウトプットをフェッチする為に、いつでも
SHOW ENGINE INNODB STATUS SQL
ステートメントを利用する事ができます。
この情報は性能調整をするうえで役立ちます。(もし
mysql インタラクティブ SQL
クライアントを利用しているなら、\G
を通常のセミコロン ステートメント
ターミネータと置き換えれば、アウトプットはより読みやすくなります。)InnoDB
ロック
モードの説明に関しては、項13.5.10.1. 「InnoDB ロック モード」
を参照してください。
mysql> SHOW ENGINE INNODB STATUS\G
InnoDB
モニタを利用する別の方法は、それらが
mysqld サーバのスタンダード
アウトプットにデータを定期的に書き込む事を許可する事です。この場合、アウトプットがクライアントに送られる事はありません。スイッチが入ると、InnoDB
モニタは大体15秒毎にデータをプリントします。サーバ
アウトプットは通常 MySQL データ
ディレクトリ内の .err
ログに導かれます。このデータは性能調整をするうえで役立ちます。Windows
上では、もしアウトプットをエラー
ログではなくウィンドウに導きたければ、--console
オプションを利用して、コンソール
ウィンドウ内のコマンド
プロンプトからサーバを起動しなければいけません。
モニタ アウトプットは次のタイプの情報を含んでいます:
各アクティブ トランザクションによって保持されるテーブルとレコード ロック
トランザクションのロック取得待ち
スレッドのセマフォ待ち
保留中のファイル I/O リクエスト
バッファ プール統計
ほとんどのシステム上で
InnoDBのメイン スレッドのパージおよび挿入バッファ マージ活動
スタンダード InnoDB
モニタに、mysqld のスタンダード
アウトプットへの書き込みをさせる為、次の SQL
ステートメントを利用してください:
CREATE TABLE innodb_monitor (a INT) ENGINE=INNODB;
次のステートメントを発行する事でモニタを停止する事ができます:
DROP TABLE innodb_monitor;
CREATE TABLE 構文は、MySQL の SQL
パーサを通してコマンドをInnoDB
エンジンに渡す手段に過ぎません:唯一問題となるのは、テーブル名
innodb_monitor
と、InnoDB
テーブルです。テーブルの構造は
InnoDB
モニタとまったく無関係です。サーバを一度シャットダウンして、再度サーバを起動しても、モニタは自動的に起動しません。再びモニタを起動するには、まずモニタ
テーブルをドロップし、そして新しい
CREATE TABLE
ステートメントを発行しなければいけません。(この構文は今後のリリース版で変更される可能性があります。)
innodb_lock_monitor
を似たような方法で利用する事ができます。これは、大量のロック情報の提供もするという事以外、innodb_monitor
と同じです。別々の
innodb_tablespace_monitor は、テーブル
スペース内に存在し、テーブル
スペース割り当てデータ構造を認証する、作成されたファイル
セグメントのリストをプリントします。さらに、InnoDB
内部データ
ディレクトリの内容をプリントする事ができる
innodb_table_monitor もあります。
InnoDB モニタ アウトプットの例:
mysql> SHOW ENGINE INNODB STATUS\G
*************************** 1. row ***************************
Status:
=====================================
030709 13:00:59 INNODB MONITOR OUTPUT
=====================================
Per second averages calculated from the last 18 seconds
----------
SEMAPHORES
----------
OS WAIT ARRAY INFO: reservation count 413452, signal count 378357
--Thread 32782 has waited at btr0sea.c line 1477 for 0.00 seconds the
semaphore: X-lock on RW-latch at 41a28668 created in file btr0sea.c line 135
a writer (thread id 32782) has reserved it in mode wait exclusive
number of readers 1, waiters flag 1
Last time read locked in file btr0sea.c line 731
Last time write locked in file btr0sea.c line 1347
Mutex spin waits 0, rounds 0, OS waits 0
RW-shared spins 108462, OS waits 37964; RW-excl spins 681824, OS waits
375485
------------------------
LATEST FOREIGN KEY ERROR
------------------------
030709 13:00:59 Transaction:
TRANSACTION 0 290328284, ACTIVE 0 sec, process no 3195, OS thread id 34831
inserting
15 lock struct(s), heap size 2496, undo log entries 9
MySQL thread id 25, query id 4668733 localhost heikki update
insert into ibtest11a (D, B, C) values (5, 'khDk' ,'khDk')
Foreign key constraint fails for table test/ibtest11a:
,
CONSTRAINT `0_219242` FOREIGN KEY (`A`, `D`) REFERENCES `ibtest11b` (`A`,
`D`) ON DELETE CASCADE ON UPDATE CASCADE
Trying to add in child table, in index PRIMARY tuple:
0: len 4; hex 80000101; asc ....;; 1: len 4; hex 80000005; asc ....;; 2:
len 4; hex 6b68446b; asc khDk;; 3: len 6; hex 0000114e0edc; asc ...N..;; 4:
len 7; hex 00000000c3e0a7; asc .......;; 5: len 4; hex 6b68446b; asc khDk;;
But in parent table test/ibtest11b, in index PRIMARY,
the closest match we can find is record:
RECORD: info bits 0 0: len 4; hex 8000015b; asc ...[;; 1: len 4; hex
80000005; asc ....;; 2: len 3; hex 6b6864; asc khd;; 3: len 6; hex
0000111ef3eb; asc ......;; 4: len 7; hex 800001001e0084; asc .......;; 5:
len 3; hex 6b6864; asc khd;;
------------------------
LATEST DETECTED DEADLOCK
------------------------
030709 12:59:58
*** (1) TRANSACTION:
TRANSACTION 0 290252780, ACTIVE 1 sec, process no 3185, OS thread id 30733
inserting
LOCK WAIT 3 lock struct(s), heap size 320, undo log entries 146
MySQL thread id 21, query id 4553379 localhost heikki update
INSERT INTO alex1 VALUES(86, 86, 794,'aA35818','bb','c79166','d4766t',
'e187358f','g84586','h794',date_format('2001-04-03 12:54:22','%Y-%m-%d
%H:%i'),7
*** (1) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 0 page no 48310 n bits 568 table test/alex1 index
symbole trx id 0 290252780 lock mode S waiting
Record lock, heap no 324 RECORD: info bits 0 0: len 7; hex 61613335383138;
asc aa35818;; 1:
*** (2) TRANSACTION:
TRANSACTION 0 290251546, ACTIVE 2 sec, process no 3190, OS thread id 32782
inserting
130 lock struct(s), heap size 11584, undo log entries 437
MySQL thread id 23, query id 4554396 localhost heikki update
REPLACE INTO alex1 VALUES(NULL, 32, NULL,'aa3572','','c3572','d6012t','',
NULL,'h396', NULL, NULL, 7.31,7.31,7.31,200)
*** (2) HOLDS THE LOCK(S):
RECORD LOCKS space id 0 page no 48310 n bits 568 table test/alex1 index
symbole trx id 0 290251546 lock_mode X locks rec but not gap
Record lock, heap no 324 RECORD: info bits 0 0: len 7; hex 61613335383138;
asc aa35818;; 1:
*** (2) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 0 page no 48310 n bits 568 table test/alex1 index
symbole trx id 0 290251546 lock_mode X locks gap before rec insert intention
waiting
Record lock, heap no 82 RECORD: info bits 0 0: len 7; hex 61613335373230;
asc aa35720;; 1:
*** WE ROLL BACK TRANSACTION (1)
------------
TRANSACTIONS
------------
Trx id counter 0 290328385
Purge done for trx's n:o < 0 290315608 undo n:o < 0 17
Total number of lock structs in row lock hash table 70
LIST OF TRANSACTIONS FOR EACH SESSION:
---TRANSACTION 0 0, not started, process no 3491, OS thread id 42002
MySQL thread id 32, query id 4668737 localhost heikki
show innodb status
---TRANSACTION 0 290328384, ACTIVE 0 sec, process no 3205, OS thread id
38929 inserting
1 lock struct(s), heap size 320
MySQL thread id 29, query id 4668736 localhost heikki update
insert into speedc values (1519229,1, 'hgjhjgghggjgjgjgjgjggjgjgjgjgjgggjgjg
jlhhgghggggghhjhghgggggghjhghghghghghhhhghghghjhhjghjghjkghjghjghjghjfhjfh
---TRANSACTION 0 290328383, ACTIVE 0 sec, process no 3180, OS thread id
28684 committing
1 lock struct(s), heap size 320, undo log entries 1
MySQL thread id 19, query id 4668734 localhost heikki update
insert into speedcm values (1603393,1, 'hgjhjgghggjgjgjgjgjggjgjgjgjgjgggjgj
gjlhhgghggggghhjhghgggggghjhghghghghghhhhghghghjhhjghjghjkghjghjghjghjfhjf
---TRANSACTION 0 290328327, ACTIVE 0 sec, process no 3200, OS thread id
36880 starting index read
LOCK WAIT 2 lock struct(s), heap size 320
MySQL thread id 27, query id 4668644 localhost heikki Searching rows for
update
update ibtest11a set B = 'kHdkkkk' where A = 89572
------- TRX HAS BEEN WAITING 0 SEC FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 0 page no 65556 n bits 232 table test/ibtest11a index
PRIMARY trx id 0 290328327 lock_mode X waiting
Record lock, heap no 1 RECORD: info bits 0 0: len 9; hex 73757072656d756d00;
asc supremum.;;
------------------
---TRANSACTION 0 290328284, ACTIVE 0 sec, process no 3195, OS thread id
34831 rollback of SQL statement
ROLLING BACK 14 lock struct(s), heap size 2496, undo log entries 9
MySQL thread id 25, query id 4668733 localhost heikki update
insert into ibtest11a (D, B, C) values (5, 'khDk' ,'khDk')
---TRANSACTION 0 290327208, ACTIVE 1 sec, process no 3190, OS thread id
32782
58 lock struct(s), heap size 5504, undo log entries 159
MySQL thread id 23, query id 4668732 localhost heikki update
REPLACE INTO alex1 VALUES(86, 46, 538,'aa95666','bb','c95666','d9486t',
'e200498f','g86814','h538',date_format('2001-04-03 12:54:22','%Y-%m-%d
%H:%i'),
---TRANSACTION 0 290323325, ACTIVE 3 sec, process no 3185, OS thread id
30733 inserting
4 lock struct(s), heap size 1024, undo log entries 165
MySQL thread id 21, query id 4668735 localhost heikki update
INSERT INTO alex1 VALUES(NULL, 49, NULL,'aa42837','','c56319','d1719t','',
NULL,'h321', NULL, NULL, 7.31,7.31,7.31,200)
--------
FILE I/O
--------
I/O thread 0 state: waiting for i/o request (insert buffer thread)
I/O thread 1 state: waiting for i/o request (log thread)
I/O thread 2 state: waiting for i/o request (read thread)
I/O thread 3 state: waiting for i/o request (write thread)
Pending normal aio reads: 0, aio writes: 0,
ibuf aio reads: 0, log i/o's: 0, sync i/o's: 0
Pending flushes (fsync) log: 0; buffer pool: 0
151671 OS file reads, 94747 OS file writes, 8750 OS fsyncs
25.44 reads/s, 18494 avg bytes/read, 17.55 writes/s, 2.33 fsyncs/s
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf for space 0: size 1, free list len 19, seg size 21,
85004 inserts, 85004 merged recs, 26669 merges
Hash table size 207619, used cells 14461, node heap has 16 buffer(s)
1877.67 hash searches/s, 5121.10 non-hash searches/s
---
LOG
---
Log sequence number 18 1212842764
Log flushed up to 18 1212665295
Last checkpoint at 18 1135877290
0 pending log writes, 0 pending chkp writes
4341 log i/o's done, 1.22 log i/o's/second
----------------------
BUFFER POOL AND MEMORY
----------------------
Total memory allocated 84966343; in additional pool allocated 1402624
Buffer pool size 3200
Free buffers 110
Database pages 3074
Modified db pages 2674
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages read 171380, created 51968, written 194688
28.72 reads/s, 20.72 creates/s, 47.55 writes/s
Buffer pool hit rate 999 / 1000
--------------
ROW OPERATIONS
--------------
0 queries inside InnoDB, 0 queries in queue
Main thread process no. 3004, id 7176, state: purging
Number of rows inserted 3738558, updated 127415, deleted 33707, read 755779
1586.13 inserts/s, 50.89 updates/s, 28.44 deletes/s, 107.88 reads/s
----------------------------
END OF INNODB MONITOR OUTPUT
============================
アウトプットの注意点:
もし
TRANSACTIONSセクションがロック待ちを報告したら、アプリケーションでロックが競合している可能性があります。このアウトプットから、トランザクションのデッドロックの原因を追跡する事もできます。e.
SEMAPHORESセクションには、セマフォを待っているスレッドと、スレッドがスピンまたは相互排他ロック(mutex)や 読み書きロックでの待機を必要とした回数に関する統計情報が報告されます。多数のスレッドがセマフォを待っている場合は、ディスク I/O またはInnoDB内部の競合が原因となっている可能性があります。競合の原因としては、多数のクエリを並行して処理しているか、OSでのスレッドのスケジューリングに問題がある事が考えられます。innodb_thread_concurrencyをデフォルト値よりも小さく設定すると、このような状況を救う事ができます。BUFFER POOL AND MEMORYセクションは読み込み、書き込みされたページの統計を提供します。.これらの数字から、クエリが現在いくつのデータ ファイル I/O 操作を行っているかを計算する事ができます。ROW OPERATIONSセクションはメインスレッドが何をしているのかを表します。
InnoDB は、バッファ オーバ
フローの可能性を避ける為に、stdout
や固定サイズ メモリ
バッファではなく、stderr
やファイルに診断アウトプットを送ります。副作用として、15秒ごとに
MySQL データ ディレクトリ内のステータス
ファイルに SHOW ENGINE INNODB STATUS
のアウトプットが書き込まれます。ファイルの名前は
innodb_status.
で、pidpid はサーバ プロセス
ID です。InnoDB
は通常のシャットダウンの為にファイルを削除します。もし異常なシャットダウンが起きたら、これらのステータス
ファイルが存在する可能性があり、それはマニュアルで削除する必要があります。それらを削除する前に、異常シャットダウンの原因に関する有益な情報を含んでいるかどうかを確認した方が良いでしょう。innodb_status.
ファイルは設定オプション
pidinnodb_status_file=1
が設定された場合のみ作成されます。
InnoDB がマルチバージョン
ストレージ エンジンなので、それはテーブル
スペース内に古いバージョンの行についての情報を保管しておく必要があります。この情報は、rollback
segment
(Oracle内の類似データ構造の後)と呼ばれるデータ構造内に格納されます。
InnoDB
は内部的にデータベース内に格納された各行に2つのフィールドを追加します。6バイト
フィールドは、行を挿入または更新した最後のトランザクションに対して、トランザクション識別子を指示します。
また、行内の特別ビットが削除されたとマークするように設定されている点で、削除は内部的に更新として扱われます。各行は、ロール
ポインタと呼ばれる7バイトのフィールドも含んでいます。そのロール
ポインタは、ロールバック
セグメントに書かれた取り消しログレコードを指し示します。もし行が更新されると、取り消しログ
レコードは行の内容が更新される前に、それを再構築する為に必要な情報を含みます。
InnoDB はトランザクション
ロールバック内で必要とされた取り消し操作を実行する為に、ロールバック
セグメント内の情報を利用します。それはまた、一貫した読み取りに対する行のこれまでのバージョンを構築する為の情報も利用します。
ロールバック
セグメント内の取り消しログは挿入と更新取り消しログに分割されます。挿入取り消しログはトランザクション
ロールバックの中でだけ必要であり、トランザクションがコミットしたらすぐに廃棄できます。更新取り消しログも一貫した読み取りの中で利用されますが、それらはトランザクションがなくなり、それに対して、一貫した読み取りの中でデータベース行のこれまでのバージョンを構築する為の更新取り消しログ内の情報を必要とするスナップショットを
InnoDB
が割り当てた後でだけ廃棄できます。
一貫した読み取りだけを発行するトランザクションを含み、トランザクションを定期的にコミットする事を覚えておく必要があります。そうでなければ、InnoDB
は更新取り消しログからデータを廃棄する事ができず、ロールバック
セグメントが大きく成長しすぎてテーブルスペースを一杯にしてしまいます。
ロールバック セグメント内の取り消しログ レコードの物質的サイズは、一般的にはそれに対応する挿入された、または更新された行よりも小さいです。ロールバック セグメントに必要な領域を計算する為にこの情報を利用する事ができます。
InnoDB マルチ バージョン
スキーム内では、行はSQL
ステートメントで削除しても、データベースから即座に物理的に削除されません。InnoDB
が削除の為に書かれた更新取り消しログ
レコードを廃棄する事ができる時だけ、それはデータベースからそれに対応する行とそのインデックスを物理的に削除する事もできます。この削除操作はパージと呼ばれる大変早い操作で、通常削除を行った
SQL ステートメントと同じ時間順をとります。
ユーザがテーブル内で大体同じくらいの比率で小さめのバッチの行を挿入、削除するというようなシナリオでは、パージ
スレッドが遅れをとり始め、そしてテーブルが大きくなり続け、全てがディスクに頼った状態になり操作がとても遅くなる可能性があります。テーブルがたったの10MB
の有効データしか持っていないとしても、たくさんの
「停止した」 行が10GB
を占めるほどにまで大きくなる事があります。そのような場合は、新しい行操作を抑圧し、パージ
スレッドにもっと多くのリソースを割り当てるのが良いでしょう。innodb_max_purge_lag
システム変数は、まさにこの目的の為に存在します。詳細については、項13.5.4. 「InnoDB 起動オプションとシステム変数」
をご参照ください。
MySQL は .frm
ファイル内のテーブルのデータ
ディレクトリ情報をデータベース
ディレクトリに格納します。これは全ての MySQL
ストレージ
エンジンに言える事です。しかし全ての
InnoDB
テーブルもテーブルスペースの内側にある
InnoDB 内部データ
ディレクトリ内にそれ自体のエントリを持っています。MySQL
がテーブルやデータベースをドロップする時、それは
.frm ファイルと
InnoDB データ
ディレクトリ内の対応するエントリの両方を削除する必要があります。これが、単に
.frm ファイルを移動するだけで
InnoDB
テーブルをデータベース間で移動する事ができない理由です。
全ての InnoDB
テーブルは、行のデータが格納されている
clustered index
と呼ばれる特別なインデックスを持っています。もし
PRIMARY KEY
をテーブル上で定義したら、主キーのインデックスは集合インデックスになります。
もしテーブルに PRIMARY KEY
を定義しなければ、MySQL は主キーとして
NOT NULL カラムだけを持つ最初の
UNIQUE
インデックスを選択し、InnoDB
がそれを集合インデックスとして利用します。もしテーブル内にそのようなインデックスがなければ、InnoDB
は、行が InnoDB
がそのようなテーブル内の行に割り当てた行 ID
によってオーダされる集合インデックスを内部的に生成します。行
ID
は、新しい行が挿入されると単調に増加する6バイトのフィールドです。従って、行
ID
によってオーダされた行は物理的に挿入順になっています。
行データはインデックス サーチが導く物と同じページ上にあるので、集合インデックスを通しての行へのアクセスは速いです。テーブルが大きいと、集合インデックス構造は従来の解決法と比較して、ディスク I/O を節約する事が多いです。(多くのデータベース システムでは、データの格納はインデックス レコードからの別のページを利用しています。)
InnoDB
では、非集合インデックス(セカンダリ
インデックスとも呼ばれる)内のレコードは、行に対して主キー値も含んでいます。InnoDB
は、この主キー値を集合インデックスから行を検索するのに利用します。もし主キーが長いと、セカンダリ
インデックスがより多くの領域を利用する事に注意して下さい。
InnoDB
は、短い方の文字列の残りの長さが領域で詰められたかのように扱われるように、長さの異なる
CHAR と VARCHAR
文字列を比較します
全ての InnoDB
インデックスは,インデックスのレコードがツリーのリーフページに格納されるB
ツリーです。インデックス ページのデフォルト
サイズは16 KB
です。新しいレコードが挿入されると、InnoDB
はページの1/16 を、将来のインデックス
レコードの挿入や更新に備えて空けようとします。
インデックス
レコードがシーケンシャル(昇順または降順)に挿入されると、インデックスページの約15/16
までがいっぱいになります。レコードがランダムに挿入された場合は、ページの1/2から15/16までがいっぱいになります。インデックス
ページの使用容量が1/2未満になると、InnoDB
はインデックス
ツリーを縮小してページを解放しようとします。
データベース アプリケーションでは、主キーが固有の識別子であり、新しい行が主キーの昇順で挿入される事が一般的です。したがって、集合インデックスへの挿入では、ディスクからのランダムな読み取りを必要としません。
一方、セカンダリ
インデックスは通常固有ではなく、セカンダリ
インデックスへの挿入は比較的ランダムな順番で行われます。
この為、InnoDB
で特別な構造が使用される事なく、多数のランダムなディスク
I/O が発生します。
固有でないセカンダリ
インデックスにインデックス
レコードが挿入される場合は、セカンダリ
インデックス ページがすでにバッファ
プール内にあるかどうかが InnoDB
によってチェックされます。すでにある場合は、InnoDB
によってインデックス
ページに直接レコードが挿入されます。バッファ
プール内にインデックス
ページがなかった場合は、InnoDB
によって特別な挿入バッファ構造にレコードが挿入されます。挿入バッファは、その全体がバッファ
プール内に収まるように小さくしてある為、このバッファへの挿入はきわめて高速です。
挿入バッファは、データベース内のセカンダリ インデックス ツリーに定期的にマージされます。インデックス ツリーの同じページ上で複数の挿入をマージする事で、ディスク I/O を削減できます。 挿入バッファによってテーブルへの挿入速度が最大15倍に高められる事が測定されています。
挿入バッファ
マージは、挿入トランザクションがコミットされた
後
まで発生し続けるでしょう。実際、これはサーバがシャットダウンし、再起動する後まで発生し続けます。(項13.5.8.1. 「InnoDB 復旧の強制」
を参照してください。)
挿入バッファ マージは、多くのセカンダリ インデックスが更新される必要があり、多くの行が挿入された時に、何時間もかかる可能性があります。この間にディスク I/O が削減され、ディスクに頼っているクエリの速度を大幅に下げる事ができます。その他の有効なバックグラウンド I/O 操作はパージ スレッドです。(項13.5.12. 「マルチバージョンの実装」 を参照してください。)
データベースのほぼ全体がメイン
メモリ内に収まる場合に、そのデータベースで最も速くクエリを実行するには、ハッシュ
インデックスを使用します。InnoDB
には、テーブルに定義されたインデックスで実行される検索を監視する構造があります。ハッシュ
インデックスの構築がクエリにとって有益であると
InnoDB
が判断した場合は、自動的にそのインデックスが構築されます。
ただし、ハッシュ
インデックスは常にテーブルに存在する B
ツリー
インデックスを基に構築されるので注意してください。InnoDB
は、B ツリー インデックスに対して
InnoDB
が検出した検索パターンに応じて、任意の長さのB
ツリーに定義されたキーの先頭部分に、ハッシュ
インデックスを構築できます。ハッシュ インデックスは部分的であってもかまいません:つまり、B
ツリー インデックス全体をバッファ
プールにキャッシュする必要はありません。InnoDB
は、頻繁にアクセスされるインデックス
ページへの要求に応じてハッシュ
インデックスを構築します。
ある意味では、柔軟なハッシュ
インデックスの構造を利用して、InnoDB
が十分に余裕のあるメイン
メモリに適応する事で、メイン メモリ
データベースの構造に近づいています。
InnoDB
テーブルの物理的なレコード構造は、テーブルが作成された時に指定された行フォーマットによって決まります。MySQL
5.1 ではデフォルトで InnoDB が
COMPACT
フォーマットを利用しますが、MySQL
の古いバージョンとの互換性を保持する為にはREDUNDANT
フォーマットが有効です。
InnoDB ROW_FORMAT=REDUNDANT
テーブル内のレコードは、次の特徴を持っています:
各インデックス レコードは6バイトのヘッダを含んでいます。このヘッダは、連続するレコードをリンクする為と、行レベル ロックで使用される。
集合インデックス内のレコードには、すべてのユーザ定義カラムのフィールドが含まれます。これに加えて、トランザクション ID 用の6バイトのフィールドと、ロール ポインタ用の7バイトのフィールドが1つずつ含まれています。
ユーザがテーブルに主キーを定義していない場合は、集合インデックスの各レコードは6バイトの行 ID フィールドも含みます。
セカンダリ インデックスの各レコードには、集合インデックス キーに対して定義されたすべてのフィールドも含まれます。
レコードには、そのレコードの各フィールドへのポインタも含まれます。レコード内のフィールド長の合計が128バイト未満の場合はポインタが1バイト、128バイト以上の場合はポインタが2バイトになります。これらのポインタの配列はレコード ディレクトリと呼ばれます。これらのポインタが指し示すエリアはレコードのデータ部分と呼ばれます。
InnoDB は内部的に固定長フォーマットの
CHAR(10)のような固定長文字カラムを格納します。InnoDB はVARCHARカラムから後続領域を切り捨てます。SQL
NULL値はレコード ディレクトリ内で1か2バイトを蓄えておきます。それ以外に、SQLNULL値は可変長カラム内に格納されるとレコードのデータ部分にゼロ バイトを蓄えます。それは固定長カラム内でレコードのデータ部分内にカラムの固定長を蓄えます。NULL値に固定領域を蓄える目的は、そうする事でインデックス ページの崩壊を起こさずにNULLからのカラムを非NULL値に、更新する事ができるという事です。
InnoDB ROW_FORMAT=COMPACT
テーブル内のレコードには次の特徴があります:
各インデックス レコードは可変長ヘッダに先導される5バイトのヘッダを含んでいます。このヘッダは、連続するレコードをリンクする為と、行レベルロックで使用されます。
レコード ヘッダは
NULLカラムを指示する為にビット ベクタを含んでいます。ビット ベクタは(n_nullable+7)/8 バイトを占めています。NULLカラムがこのベクタ内のビット以外の領域を占める事はありません。各非
NULL可変長フィールドに対して、レコード ヘッダは1か2バイトのカラム長を含みます。カラムの一部が外部的に格納されたり、最大長が255バイトを超える、または実際の長さが127バイトを超えたりしなければ2バイトだけ必要になります。レコード ヘッダにはカラムのデータ内容が続きます。
NULLのカラムは省略されます。集合インデックス内のレコードには、すべてのユーザ定義カラムのフィールドが含まれます。これに加えて、トランザクション ID 用の6バイトのフィールドと、ロール ポインタ用の7バイトのフィールドが1つずつ含まれています。
ユーザがテーブルに主キーを定義していない場合は、集合インデックスの各レコードは6バイトの行 ID フィールドも含みます。
セカンダリ インデックスの各レコードには、集合インデックス キーに対して定義されたすべてのフィールドも含まれます。
InnoDB は内部的に固定長フォーマットの
CHAR(10)のような固定長、固定幅文字カラムを格納します。InnoDB はVARCHARカラムから後続領域を切り捨てます。InnoDB は、後続領域を切り取る事で内部的に UTF-8
CHAR(カラムをn)nバイトで格納しようとします。ROW_FORMAT=REDUNDANT内では、そのようなカラムは3*nバイトを占めます。最小領域nを蓄える目的は、これによって多くの場合、インデックス ページの崩壊を起こさずにカラムの更新ができるからです。
InnoDB は、擬似非同期 I/O
を使用します:InnoDB は、多数の I/O
スレッドを作成して、先読みなどの I/O
操作に対応します。
InnoDB
には2つの先読みヒューリスティックがあります:
シーケンシャル先読みでは、
InnoDBがテーブル スペース内のセグメントへのアクセス パターンがシーケンシャルである事に 気づくと、I/O システムにデータベース ページの読み取りバッチをあらかじめ連絡します。任意の先読みでは、
InnoDBがテーブル スペース内のいくつかのスペースがバッファ プールに完全に読み取られている最中である事に気づくと、I/O システムに残りの読み取りを連絡します。
InnoDB は
二重書き込み
と呼ばれる新しいファイル フラッシュ
テクニックを利用します。.これは、OS
のクラッシュや停電後の復旧に安全性を追加し、また
fsync()
オペレーションの必要性を削減する事で
ほとんどの種類の Unix の性能を向上させます。
二重書き込みとは、データ
ファイルにページを書き込む前に、InnoDB
が最初にそれらを二重書き込みバッファと呼ばれる隣接するテーブルスペース
エリアに書き込む事を意味します。二重書き込みバッファへの書き込みとフラッシュが完了した後に
InnoDB はデータ
ファイル内の正しい位置にページを書き込みます。もし
OS
がページ書き込みの最中にクラッシュしたら、InnoDB
は復旧の最中に二重書き込みバッファからページの有効なコピーを見つける事ができます。
設定ファイルに定義するデータ
ファイルから、InnoDB のテーブル
スペースが構成されます。これらのファイルは、単純に連結されてテーブルスペースになります。ストライピングは使用されません。現時点では、テーブルスペースのどの位置にテーブルが割り当てられるかを定義できません。しかし、新たに作成されるテーブルスペース内では、InnoDB
が最初のデータ
ファイルから領域を割り当てます。
テーブルスペースは、デフォルト サイズが16 KB
のデータベース ページで構成されます。
これらのページは、64個の連続するページから成るエクステントにグループ化されます。InnoDB
では、テーブルスペース内部の 「files」
を セグメント
と呼びます。これは実際には多くのテーブルスペース
セグメントを含んでいる為、「ロールバック
セグメント」という名前は、多少誤解を招くおそれがあります。
InnoDB
では、各インデックスに2つのセグメントが割り当てられます。1つは
B ツリーの非リーフ ノード用、もう1つはリーフ
ノード用です。これには、データを含んでいるリーフ
ノードで連続性を高める意図があります。
テーブルスペース内でセグメントが大きくなると、InnoDB
はそのセグメントに最初の32ページを個別に割り当てます。InnoDB
はその後、エクステント全体をセグメントに割り当て始めます。InnoDB
では、データの連続性を確保する為に、大きなセグメントに一度に最大4つのエクステントを追加できます。
テーブルスペースには、他のページのビットマップを含んだページがある為、InnoDB
テーブルスペース内のいくつかのエクステントは、全体としてではなく個別のページとしてのみセグメントに割り当てる事ができます。
SHOW TABLE STATUS
ステートメントを発行してテーブルスペース内の空き領域を照会すると、InnoDB
からテーブルスペース内の完全に空いているエクステントが報告されます。InnoDB
は、常にいくつかのエクステントをクリーンアップとその他の内部的な用途の為に確保しており、これらのエクステントは空き領域に含まれません。
テーブルからデータを削除すると、InnoDB
によって対応する B ツリー
インデックスが縮小されます。これによって、他のユーザが開放された領域を利用できるようになるかどうかは、削除のパターンがテーブルスペースの個々のページやエクステントを開放するかどうかによって異なります。テーブルを破棄したり、またはテーブルからすべての行を削除すると、他のユーザに確実に領域が解放されますが、削除された行は、トランザクション
ロールバックまたは一貫した読み取りでそのレコードが必要なくなった後のパージ操作で初めて物理的に削除されるという事に注意してください(詳しくは
項13.5.12. 「マルチバージョンの実装」
を参照してください。)
テーブルのインデックスでランダムな挿入または削除が行われると、インデックスがフラグメント化される事があります。フラグメント化とは、ディスクでのインデックス ページの物理的な順序が、ページでのレコードのインデックス順とかけ離れている事、またはインデックスに割り当てられた64ページのブロック内に多数の未使用ページがある事を意味します。
フラグメント化の兆候は、テーブルが
「必要とする」
以上の領域を取るという事です。それがどの程度なのかという事を正確に決めるのは困難です。全ての
InnoDB データとインデックスは B
ツリー内に格納され、それらの充てん比は50%
から100% で異なっています。
その他のフラグメント化の兆候は、このようなテーブルスキャンに 「必要」 以上の時間がかかるという事です。
SELECT COUNT(*) FROM t WHERE a_non_indexed_column <> 12345;
(前出のクエリの中で、SQL オプチマイザはセカンダリ インデックスではなく、集合インデックスのスキャンの中で 「欺かれて」 います。)ほとんどのディスクが1秒に付き10から50 MB で読み込む事ができ、それでテーブル スキャンがどれくらいのスピードで起動しなければいけないかを概算します。
それは 「null」 ALTER TABLE
操作を定期的に実行すればインデックス
スキャンの速度を上げる事ができます:
ALTER TABLE tbl_name ENGINE=INNODB
それによって MySQL はテーブルを再構成します。デフラグ操作を行う別の方法は、テーブルをテキスト ファイルにダンプし、テーブルをドロップし、そしてそれをダンプ ファイルから再ロードする為に mysqldump を利用する事です。
インデックスへの挿入が常に昇順で行われ、レコードが必ず末尾から削除される場合は、InnoDB
のファイル領域管理アルゴリズムによってインデックスのフラグメント化が発生しない事が保証されます。
InnoDB でのエラー処理は、必ずしも
SQL
スタンダードに明記されている通りではありません。スタンダードによると、SQL
ステートメントでエラーが発生した場合は、その
SQL
ステートメントでロールバックを実行するように記述されています。InnoDB
では、ステートメントの一部のみ、またはトランザクション全体がロールバックされる事があります。
次の項目は、InnoDB
でのエラー処理の仕様を説明しています:
テーブルスペース内でファイル領域を使い果たすと、MySQL の
Table is fullエラーが発生し、InnoDBが SQL ステートメントをロールバックします。トランザクション デッドロックが発生すると、
InnoDBがトランザクション全体をロールバックします。 ロック待ちタイムアウトが起きた場合は、InnoDBは最新の SQL ステートメントだけをロールバックします。トランザクション ロールバックが、デッドロックやロック待ちタイムアウトによって引き起こされると、それはトランザクション内のステートメントの効果をキャンセルします。しかし、トランザクション開始ステートメントが
START TRANSACTIONかBEGINステートメントであると、ロールバックはこのステートメントをキャンセルしません。さらなる SQL は、暗黙のコミットを引き起こすCOMMIT、ROLLBACK、またはいくつかの SQL ステートメントが発生するまでの間トランザクションの一部になります。ステートメント内で
IGNOREオプションを指定しなければ、複製キー エラーは SQL ステートメントをロールバックします。row too long errorは SQL ステートメントをロールバックします。その他のエラーは主に MySQL のコード レイヤ(
InnoDBストレージ エンジン レベルの上)によって検出され、対応する SQL ステートメントがロールバックされます。ロックは単一 SQL ステートメントのロールバック内でリリースされません。
暗黙のロールバックの最中に、明示的な
ROLLBACK SQL
コマンドの実行の最中と同じように、SHOW
PROCESSLIST は関連する接続の
State カラム内でRolling
back を表示します。
次にある物は、今後直面するであろう主な
InnoDB
特有エラーの非消耗リストと、それらがなぜ起きるのか、そしてその問題をどのように解決するのかについての情報です。
1005 (ER_CANT_CREATE_TABLE)テーブルを作成できません。もしエラー メッセージが
errno150を参照していたら、外部キー制約が正しく形成さられなかった為にテーブル作成は失敗しました。もしエラー メッセージがerrno-1を参照していたら、テーブルが内部 InnoDB テーブルの名前と一致するカラム名を含んでいる為にテーブル作成はおそらく失敗したでしょう。1016 (ER_CANT_OPEN_FILE)InnoDBテーブルに対する.frmファイルが存在しているとしても、InnoDBデータ ファイルからInnoDBを見つける事はできません。詳しくは 項13.5.17.1. 「トラブルシューティングInnoDBデータ ディクショナリ操作」 を参照してください。1114 (ER_RECORD_FILE_FULL)InnoDBはテーブルスペース内で空き領域を使い果たしました。新しいデータ ファイルを追加する為にテーブルスペースを再設定しなければいけません。1205 (ER_LOCK_WAIT_TIMEOUT)ロック待ちタイムアウトが失効しました。トランザクションがロールバックされました。
1213 (ER_LOCK_DEADLOCK)トランザクション デッドロック。トランザクションを返さなければいけません。
1216 (ER_NO_REFERENCED_ROW)行を追加しようとしているのに親行がなく、外部キー制約が失敗します。まず親行を追加しなければいけません。
1217 (ER_ROW_IS_REFERENCED)子供を持つ親行を削除しようとしていて、外部キー制約が失敗します。子供を先に削除する必要があります。
OS エラー番号の意味をプリントする為に、MySQL ディストリビューションに付属している perror プログラムを利用してください。
次のテーブルにはいくつかの主な Linux システム エラー コードが紹介されています。完全なリストに関しては、Linux ソース コード を参照してください。
1 (EPERM)許可されていない操作
2 (ENOENT)そのようなファイルやディレクトリは存在しない
3 (ESRCH)そのような処理は存在しない
4 (EINTR)妨害されたシステム コール
5 (EIO)I/O エラー
6 (ENXIO)そのようなデバイスやアドレスは存在しない
7 (E2BIG)Arg リストが大きすぎる
8 (ENOEXEC)Exec フォーマット エラー
9 (EBADF)不良ファイル番号
10 (ECHILD)子供の処理がない
11 (EAGAIN)再度試してください
12 (ENOMEM)メモリ不足
13 (EACCES)許可が却下された
14 (EFAULT)不良アドレス
15 (ENOTBLK)ブロック デバイスが要求された
16 (EBUSY)デバイスかリソースがビジー
17 (EEXIST)ファイルが存在する
18 (EXDEV)クロス デバイス リンク
19 (ENODEV)そのようなデバイスは存在しない
20 (ENOTDIR)ディレクトリではない
21 (EISDIR)ディレクトリである
22 (EINVAL)無効引数
23 (ENFILE)ファイル テーブル オーバーフロー
24 (EMFILE)オープン ファイルが多すぎる
25 (ENOTTY)デバイスの不適切な ioctl
26 (ETXTBSY)テキスト ファイルがビジー
27 (EFBIG)ファイルが大きすぎる
28 (ENOSPC)デバイスに領域が残っていない
29 (ESPIPE)不正シーク
30 (EROFS)読み込み専用ファイル システム
31 (EMLINK)リンクが多すぎる
次のテーブルにはいくつかの主な Windows システム エラー コードが紹介されています。完全なリストに関しては Microsoft ウェブ サイト を参照してください。
1 (ERROR_INVALID_FUNCTION)不正関数です。
2 (ERROR_FILE_NOT_FOUND)システムは指定されたファイルを見つける事ができません。
3 (ERROR_PATH_NOT_FOUND)システムは指定されたパスを見つける事ができません。
4 (ERROR_TOO_MANY_OPEN_FILES)システムはファイルを開く事ができません。
5 (ERROR_ACCESS_DENIED)アクセスは却下されました。
6 (ERROR_INVALID_HANDLE)ハンドルが無効です。
7 (ERROR_ARENA_TRASHED)ストレージ コントロール ブロックは破壊されました。
8 (ERROR_NOT_ENOUGH_MEMORY).このコマンドを処理する充分なストレージがありません。
9 (ERROR_INVALID_BLOCK)ストレージ コントロール ブロック アドレスが無効です。
10 (ERROR_BAD_ENVIRONMENT)環境が不適切です。
11 (ERROR_BAD_FORMAT)不適切なフォーマットによってプログラムのロードを行おうとしました。
12 (ERROR_INVALID_ACCESS)アクセス コードが不正です。
13 (ERROR_INVALID_DATA)データが無効です。
14 (ERROR_OUTOFMEMORY).この操作を完了する充分なストレージがありません。
15 (ERROR_INVALID_DRIVE)システムは指定されたドライブを見つける事ができません。
16 (ERROR_CURRENT_DIRECTORY)ディレクトリを削除できません。
17 (ERROR_NOT_SAME_DEVICE)システムはファイルを別のディスク ドライブに移動できません。
18 (ERROR_NO_MORE_FILES)これ以上ファイルはありません。
19 (ERROR_WRITE_PROTECT)メディアは書き込み保護されています。
20 (ERROR_BAD_UNIT)システムは指定されたデバイスを見つける事ができません。
21 (ERROR_NOT_READY)デバイスの準備ができていません。
22 (ERROR_BAD_COMMAND)デバイスはコマンドを認識しません。
23 (ERROR_CRC)データ エラー (サイクリック リダンダンシー チェック)
24 (ERROR_BAD_LENGTH)プログラムがコマンドを発行したましたがコマンド長が不適切です。
25 (ERROR_SEEK)ドライブはディスク上に特定のエリアやトラックをロケートできません。
26 (ERROR_NOT_DOS_DISK)特定のディスクやディスケットにアクセスできません。
27 (ERROR_SECTOR_NOT_FOUND)ドライブはリクエストされたセクタを見つける事ができません。
28 (ERROR_OUT_OF_PAPER)プリンタの紙切れです。
29 (ERROR_WRITE_FAULT)システムは指定されたデバイスに書き込む事ができません。
30 (ERROR_READ_FAULT)システムは指定されたデバイスから読み込む事ができません。
31 (ERROR_GEN_FAILURE)システムに添付されたデバイスが機能していません。
32 (ERROR_SHARING_VIOLATION)別の処理で利用されている為ファイルにアクセスできません。
33 (ERROR_LOCK_VIOLATION)別の処理がファイルの一部をロックした為にファイルにアクセスできません。
34 (ERROR_WRONG_DISK)不正なディスケットがドライブ内にあります。挿入 %2 (ボリューム通し番号:%3) ドライブ内に %1
36 (ERROR_SHARING_BUFFER_EXCEEDED)共有の為に開かれたファイルが多すぎます。
38 (ERROR_HANDLE_EOF)ファイルの最後に到達しました。
39 (ERROR_HANDLE_DISK_FULL)ディスクが一杯です。
87 (ERROR_INVALID_PARAMETER)パラメータが不正です。(もしこのエラーが Windows で起き、サーバ オプション ファイル内で
innodb_file_per_tableを有効にしたら、ラインinnodb_flush_method=unbufferedをファイルにも追加してください。)112 (ERROR_DISK_FULL)ディスクが一杯です。
123 (ERROR_INVALID_NAME)ファイル名、ディレクトリ名、またはボリューム ラベル構文が不適切です。
1450 (ERROR_NO_SYSTEM_RESOURCES)要求されたサービスを完了する為のシステム リソースが充分ではありません。
警告:MySQL システムテーブルを
mysqlデータベースの中でMyISAMからInnoDBテーブルに変換 しない でください!これはサポートされていない操作です。もしこれをしてしまうと、バックアップから古いシステム テーブルを復旧するか、mysql_install_db スクリプトを利用してそれらを再生成するまで MySQL は再起動しません。テーブルが1000 以上のカラムを含む事はできません。
内部的な最大キー長は3500バイトですが、MySQL 自体はそれを1024バイトに制限しています。
VARCHAR、BLOBそしてTEXTカラム以外の最大行長は、データベース ページの半分よりも少し短いです。これは、最大行長は約8000バイトであるという事です。LONGBLOBとLONGTEXTカラムは4GB 以下である必要があり、BLOBとTEXTカラムを含んだ合計行長は4GB 以下でなければいけません。InnoDBが行内のVARCHAR、BLOB、またはTEXTカラムの最初の768バイトを格納し、残りは別のページに格納されます。InnoDBは内部的にサイズ65535以上の行をサポートしますが、65535以上のサイズのVARCHARカラムを含む行を定義する事はできません:mysql>
CREATE TABLE t (a VARCHAR(8000), b VARCHAR(10000),->c VARCHAR(10000), d VARCHAR(10000), e VARCHAR(10000),->f VARCHAR(10000), g VARCHAR(10000)) ENGINE=InnoDB;ERROR 1118 (42000): Row size too large. The maximum row size for the used table type, not counting BLOBs, is 65535. You have to change some columns to TEXT or BLOBsいくつかの古い OS では、ファイルは2GB 以下でなければいけません。これは
InnoDB自体の制限ではありませんが、もし大きいテーブルスペースを要求すると、1つではなく複数の小さいデータ ファイルを利用してそれを設定するか、または大きいデータ ファイルをファイルしなければいけません。結合した
InnoDBログ ファイルのサイズは4GB 以下でなければいけません。最小テーブルスペース サイズは10MB です。最大テーブルスペース サイズは40億データベース ページ(64TB)です。これはテーブルにとっても最大サイズです。
InnoDBテーブルはFULLTEXTインデックスをサポートしません。InnoDBテーブルは空間タイプはサポートしますが、そのインデックスはサポートしません。ANALYZE TABLEは、各インデックス ツリーにランダムにダイブし、インデックス濃度概算をそれに応じて更新する事で、インデックス濃度(SHOW INDEXアウトプットのCardinalityカラム内に表示されるように)を決定します。これらは単なる概算である為、ANALYZE TABLEを繰り返す事で別の数値が導かれる事があると覚えておいてください。これによってANALYZE TABLEのInnoDBテーブル上での速度は速くなりますが、全ての行を考慮する訳ではないので100% 正確とは言えません。MySQL はインデックス濃度概算を結合最適化でしか利用しません。いくつかの結合が正しい方法で最適化されなければ、
ANALYZE TABLEを利用してみると良いでしょう。ANALYZE TABLEが特定のテーブルに十分な値を発行しなかった場合、特定のインデックスの利用を強制する為にクエリとFORCE INDEXを共に利用するか、または MySQL がテーブル スキャンよりもインデックス検索を好む事を保証する為にmax_seeks_for_keyシステム変数を設定する事ができます。項4.2.3. 「システム変数」 と 項B.1.6. 「Optimizer-Related Issues」 を参照して下さい。SHOW TABLE STATUSはテーブルが確保した物理サイズ以外、InnoDBテーブルに、正確な統計を与えません。行カウントは SQL 最適化で利用される単なる概算です。InnoDBはテーブル内の行の内部カウントを保持しません。(実際は、マルチ バージョンの為、少々複雑になります。)SELECT COUNT(*) FROM tステートメントを処理する為に、InnoDBはテーブルのインデックスをスキャンする必要があり、それはもしインデックスが完全にバッファ プールの中に無いのであれば時間がかかります。 速いカウントの為には、自分で作成したカウンタ テーブルを利用し、そのカウンタが行う挿入と削除に従ってアプリケーションを更新させなければいけません。テーブルが頻繁に変更されないのであれば、MySQL クエリ キャッシュを利用するのが良い解決法です。もし行カウントの概算で充分であれば、SHOW TABLE STATUSを利用する事もできます。詳しくは 項13.5.11. 「InnoDBパフォーマンス チューニング ヒント」 を参照してください。Windows 上では
InnoDBはいつもデータベースとテーブル名を小文字で内部的に格納します。Unix から Windows に、または Windows から Unix にデータベースをバイナリ フォーマットで移動するには、データベースとテーブルを作成する時に必ず明示的に小文字の名前を利用する必要があります。AUTO_INCREMENTカラムに対しては、テーブルにインデックスを常に定義する必要があり、そしてそのインデックスはAUTO_INCREMENTカラムだけを含んでいなければいけません。MyISAMテーブル内では、AUTO_INCREMENTカラムは複合カラム インデックスの一部であるかもしれません。テーブル上であらかじめ指定された
AUTO_INCREMENTカラムを初期化している間、InnoDBはAUTO_INCREMENTカラムと関係しているインデックスの最後に専用ロックを設定します。自動インクリメント カウンタにアクセスする時、
InnoDBは、トランザクション全体の最後までではなく、現在の SQL ステートメントの最後まで続く、特別なテーブル ロック モードAUTO-INCを利用します。AUTO-INCテーブル ロックが行われている間は、別のクライアントはテーブルに挿入ができない事に注意してください。 項13.5.10.2. 「InnoDBとAUTOCOMMIT」 を参照してください。MySQL サーバを再起動する時、
InnoDBはAUTO_INCREMENTカラムの為に生成されたが、格納はされなかった古い値を再利用するかもしれません。(それは、ロールバックされた古いトランザクション内で生成された値です。)AUTO_INCREMENTカラムが値を使い果たした時、InnoDBはBIGINTを-9223372036854775808に、そしてBIGINT UNSIGNEDを1に切り上げます。しかし、BIGINT値は64ビットあるので、もし1秒に100万行挿入しようとすると、BIGINTがその上限に達するまで3百万年ほどかかるという事を覚えておいてください。その他の全ての整数タイプ カラムを利用すると、複製キー エラーが発生します。これは最も一般的な MySQL 性能であり、特定のストレージ エンジンに関する事ではないので、MyISAMの機能の仕方と似ています。DELETE FROMはテーブルを再生成しませんが、その代わりに全ての行を1つ1つ削除します。tbl_name状況によっては、
InnoDBテーブルのTRUNCATEはtbl_nameDELETE FROMにマップされ、tbl_nameAUTO_INCREMENTカウンタをリセットしません。詳しくは 項12.2.9. 「TRUNCATE構文」 を参照してください。MySQL 5.1 では、もし
innodb_table_locks=1(デフォルト)であれば、MySQLLOCK TABLES操作は各テーブルに2つのロックを取得します。 MySQL レイヤのテーブル ロックに加えて、それはInnoDBテーブル ロックも取得します。MySQL の古いバージョンはInnoDBテーブルロックを取得しませんでした。innodb_table_locks=0を設定する事で古いバージョンを選択する事ができます。もしInnoDBテーブル ロックが取得されなければ、テーブルのいくつかのレコードが別のトランザクションによってロックされなくてもLOCK TABLESが完了します。トランザクションによって保持される全ての
InnoDBロックは、トランザクションがコミットされた時か異常終了した時にリリースされます。従って、取得されたInnoDBテーブル ロックは直ちにリリースされるので、LOCK TABLESをAUTOCOMMIT=1モードのInnoDBテーブル上で呼び出す意味はありません。トランザクションの最中にさらにテーブルをロックするのが有効な場合があります。残念ながら、MySQL 内の
LOCK TABLESは暗黙のCOMMITとUNLOCK TABLESを実行します。LOCK TABLESのInnoDB変異形は、トランザクションの最中で実行できるように作られています。複製スレーブ サーバを設定する為の
LOAD TABLE FROM MASTERステートメントはInnoDBテーブルには機能しません。次善策は、マスタ上でテーブルをMyISAMに変更し、それをロードし、その後マスタ テーブルを再度InnoDBに戻すという方法です。もしテーブルが、外部キーなどのようなInnoDB特有の特徴を利用していたら、これは行わないでください。InnoDB内のデフォルト データベース ページ サイズは16KB です。コードを再コンパイルする事で、8KB から64KB の範囲の値に設定する事ができます。univ.iソース ファイル内でUNIV_PAGE_SIZEとUNIV_PAGE_SIZE_SHIFTの値を更新しなければいけません。トリガは現在、転送された外部キー アクションによって有効化されません。
次の一般的なガイドラインは、トラブルシューティング
InnoDB 問題に適応します:
操作に失敗したり、バグの疑いがある時は、
.errのサフィックスを持つデータ ディレクトリ内のファイルである、MySQL サーバ エラー ログを確認する必要があります。トラブルシューティングを行う時は、通常、mysqld_safe ラッパを通したり、Windows サービスとしてではなく、コマンド プロンプトから MySQL サーバを起動するのが一番良い方法です。そうする事で mysqld がコンソールに何をプリントするのかを確認でき、何が起きているのかをよく知る事ができます。Windows 上では、アウトプットをコンソール ウィンドウに導く為に
--consoleオプションを利用してサーバを起動させる必要があります。問題についての情報を得る為には
InnoDBモニタを利用してください。(項13.5.11.1. 「SHOW ENGINE INNODB STATUSとInnoDBモニタ」 を参照してください。)もしその問題が性能に関連していたり、サーバがハングアップしているようであれば、InnoDB内部の状態に関する情報をプリントする為にinnodb_monitorを利用しなければいけません。もしその問題がロックに関連していたら、innodb_lock_monitorを利用してください。もしその問題がテーブル作成や別のデータ ディレクトリ操作に関連していたら、InnoDB内部データ ディクショナリの内容をプリントする為にinnodb_table_monitorを利用してください。もしテーブルが破損した疑いがあれば、そのテーブル上で
CHECK TABLEを起動してください。
MySQL Enterprise MySQL ネットワークモニタリングとアドバイスサービスは、InnoDB テーブルをモニタする為に特別にデザインされたアドバイザを提供します。これらのアドバイザは、今後起こる可能性のある問題を前もって指摘できる場合があります。追加情報については http://www-jp.mysql.com/products/enterprise/advisors.html を参照してください。
テーブルに関する特定の問題点は、MySQL
サーバが、データベース
ディレクトリ内に格納する .frm
ファイル内にデータ
ディクショナリ情報を保存する一方、InnoDB
もまたテーブルスペース
ファイル内にあるそれ自体のデータ
ディクショナリに情報を格納するという事です。もし
.frm
ファイルを移動させたり、サーバがデータ
ディクショナリ操作の最中にクラッシュしたりすると、.frm
ファイルの場所は、InnoDB
内部データ
ディクショナリ内に記録された場所と同期しなくなってしまうかもしれません。
同期していないデータ
ディクショナリの兆候は、CREATE
TABLE
ステートメントが失敗する事です。もしこれが起こったら、サーバのエラー
ログを確認する必要があります。もしログが、テーブルは既に
InnoDB
内部データディクショナリ内に存在すると報告すると、対応する
.frm ファイルを持たない
InnoDB テーブルスペース
ファイル内に孤立テーブルを持つという事になります。エラー
メッセージはこのようになります:
InnoDB: Error: table test/parent already exists in InnoDB internal InnoDB: data dictionary. Have you deleted the .frm file InnoDB: and not used DROP TABLE? Have you used DROP DATABASE InnoDB: for InnoDB tables in MySQL version <= 3.23.43? InnoDB: See the Restrictions section of the InnoDB manual. InnoDB: You can drop the orphaned table inside InnoDB by InnoDB: creating an InnoDB table with the same name in another InnoDB: database and moving the .frm file to the current database. InnoDB: Then MySQL thinks the table exists, and DROP TABLE will InnoDB: succeed.
エラー
メッセージで指示された方法に従えば、孤立テーブルをドロップする事ができます。もしまだ
DROP TABLE
を無事にに利用できないのであれば、その問題は
mysql
クライアント内での名前の完了に原因があるかもしれません。この問題を解決するには、--skip-auto-rehash
オプションを利用して mysql
クライアントを開始し、もう一度 DROP
TABLE
を実行してみてください。(名前の完了がオンになっていると、mysql
は今説明したような問題が存在する時に失敗する、テーブル名のリストを構築しようとします。)
同期していないデータ
ディクショナリのその他の兆候は、.InnoDB
ファイルを開く事ができないエラーを MySQL
がプリントする事です:
ERROR 1016: Can't open file: 'child2.InnoDB'. (errno: 1)
エラー ログ内に次のようなメッセージが表示されます:
InnoDB: Cannot find table test/child2 from the internal data dictionary InnoDB: of InnoDB though the .frm file for the table exists. Maybe you InnoDB: have deleted and recreated InnoDB data files but have forgotten InnoDB: to delete the corresponding .frm files of InnoDB tables?
これは InnoDB
内に、対応するテーブルを持たない孤立した
.frm
ファイルがある事を意味します。孤立した
.frm
ファイルは、マニュアルで削除する事でドロップできます。
もし MySQL が ALTER TABLE
操作の最中でクラッシュしたら、InnoDB
テーブルスペースの中に孤立したテンポラリ
テーブルができてしまうかもしれません。innodb_table_monitor
を利用して、#sql-...
が誰の名前なのかが表示されたテーブルのリストを確認する事ができます。名前をバックフォートで囲めば、文字
‘#’
を名前に含んでいるテーブル上で SQL
ステートメントを実行する事ができます。したがって、先ほど説明した方法で、そのような孤立テーブルを他の孤立テーブルと同じようにドロップする事ができます。Unix
シェル内でファイルをコピーしたりリネームしたりするには、もしファイル名が
‘#’
を含んでいたら、ファイル名を二重引用符で囲まなければいけない事を覚えておいてください。
MRG_MyISAMエンジンとしても知られているMERGE
ストレージエンジンは、一つの物として使用する事ができる同一のMyISAM
テーブルの集まりです。「同一の」というのは、全てのテーブルが同一のカラムとインデックス情報を持つという意味です。カラムのリストされている順番が違っていたり、カラムが完全に一致していなかったり、インデックスの順番が違っていたりするとMyISAM
テーブルをマージする事はできません。しかし、全てのMyISAM
テーブルはmyisampackで圧縮する事ができます。詳しくは項7.6. 「myisampack ? 圧縮された、読み取り専用MyISAM テーブルを作成する。」を参照してください。AVG_ROW_LENGTH、
MAX_ROWS、または PACK_KEYS
等のようなテーブルオプションの違いは問題ではありません。
MERGE
テーブルを作成する時、MySQLはディスク上に二つファイルを作成します。そのファイル名はテーブル名で始まり、ファイルタイプを指示する拡張子が付きます。.frm
ファイルはテーブルフォーマットを格納し、.MRG
ファイルは一つの物として使用されるべきテーブルの名前を含んでいます。それらのテーブルは、MERGE
テーブルそのものと同じデータベースになくてはならないという訳ではありません。
MERGEテーブル上では、SELECT、
DELETE、 UPDATE、そして
INSERTを利用する事ができます。MERGE
テーブルにマップするMyISAM
テーブル上に、 SELECT、
UPDATE、そして DELETE
権限を持たなければいけません。
注意
MERGE
テーブルの利用は、次のセキュリティに関する問題を引き起こします。ユーザが
MyISAM テーブル
tにアクセスする事ができる時、そのユーザは
tにアクセスする事ができるMERGE
テーブル
mを作成する事ができます。しかし、もしユーザのtに対する特権が後で破棄されるなら、mにアクセスする事でtにアクセスし続ける事ができます。もしこの作業が好ましくなければ、MERGE
ストレージエンジンを無効にする為に、新しい--skip-merge
オプションを使ってサーバをスタートさせる事ができます。このオプションはMySQL
5.1.12.以降で利用できます。
MERGE
テーブルをDROPする時、
MERGE 仕様だけが削除されます。
基礎となるテーブルは影響を受けません。
MERGE テーブルを作成するには、どの
MyISAM
テーブルを一つの物として利用したいかを示すUNION=(
条項を指定しなければいけません。list-of-tables)MERGE
テーブルに、 UNION
リストの最初か最後のテーブルに位置する為の挿入が必要であれば、自由に
INSERT_METHOD
オプションを指定する事ができます。テーブルの最初か最後に挿入されるように、FIRST
か
LAST値をそれぞれ使用してください。INSERT_METHOD
オプションを指定しない場合や、NOの値で指定した場合は、MERGEテーブルに行を挿入しようとしてもエラーが発生します。
次の例は、MERGE
テーブルの作成方法を紹介しています。
mysql>CREATE TABLE t1 (->a INT NOT NULL AUTO_INCREMENT PRIMARY KEY,->message CHAR(20)) ENGINE=MyISAM;mysql>CREATE TABLE t2 (->a INT NOT NULL AUTO_INCREMENT PRIMARY KEY,->message CHAR(20)) ENGINE=MyISAM;mysql>INSERT INTO t1 (message) VALUES ('Testing'),('table'),('t1');mysql>INSERT INTO t2 (message) VALUES ('Testing'),('table'),('t2');mysql>CREATE TABLE total (->a INT NOT NULL AUTO_INCREMENT,->message CHAR(20), INDEX(a))->ENGINE=MERGE UNION=(t1,t2) INSERT_METHOD=LAST;
基礎となっている MyISAM
テーブルの中で、a
カラムはPRIMARY
KEYとしてインデックスされていますが、MERGE
テーブルの中ではそうではない事に注意してください。MERGE
テーブルは、基礎となるテーブルに対して一意性を実行することができないので、インデックスはされるのですが、それはPRIMARY
KEYとしてではないのです。
In MySQL 5.1.15
とそれ以降のバージョンでは、MERGEテーブルの一部であるテーブルが開かれる時に次のチェックが行われます。もし一つでも適合性チェックに失敗したら、そのテーブルを開く事はできません。それぞれのテーブルに適応される適合性チェックは次のような物です。
MERGEテーブルとまったく同じカラム数がなければいけません。MERGEテーブルのカラムの順番は、基礎となるテーブルのカラムの順番と一致しなければいけません。さらに、親
MERGEテーブルと、基礎となるテーブルのカラム仕様がそれぞれ比較されます。それぞれのカラムに対して、 MySQL は次のような事を確認します。基礎となるテーブルのカラムタイプは、
MERGEテーブルのカラムタイプと等しい。基礎となるテーブルのカラムの長さは、
MERGEテーブルのカラムの長さと等しい。基礎となるテーブルのカラムと
MERGEテーブルのカラムはNULLとなり得る。
基礎となるテーブルは、少なくてもマージテーブルと同量のキーを持つ必要がある。基礎となるテーブルは、
MERGEよりも多量のキーを持つ事はできますが、その反対はできません。それぞれのキーに対して
基礎となるテーブルのキータイプがマージテーブルのキータイプと等しいかどうかチェックして下さい。
基礎となるテーブルのキー定義中のキーパーツ(例 合成キー内の複数カラム)数が、マージテーブルのキー定義中のキーパーツ数を等しいかどうかチェックして下さい。
それぞれのキーパーツに対して
キーパーツの長さが等しいかどうか確認してください。
キーパーツタイプが等しいかどうか確認してください。
キーパーツの言語が等しいかどうか確認してください。
キーパーツが
NULLになり得るかどうか確認してください。
MERGE
テーブルを作成した後、テーブルグループに対してまとめて機能するクエリを発行する事ができます。
mysql> SELECT * FROM total;
+---+---------+
| a | message |
+---+---------+
| 1 | Testing |
| 2 | table |
| 3 | t1 |
| 1 | Testing |
| 2 | table |
| 3 | t2 |
+---+---------+
MERGE
テーブルを再度別のMyISAMテーブルのグループに対してマップするには、次の方法の一つを利用する事ができます。
MERGEテーブルをDROPして、もう一度作成してください。基礎となるテーブルのリストを変更する為に
ALTER TABLEを利用して下さい。tbl_nameUNION=(...)
MERGE
テーブルは、次のような問題を解決するのに役立ちます。
ログテーブル一式を簡単に処理する事ができます。例えば、違う月のデータを別々のテーブルに入力し、myisampackを利用してそれらを圧縮し、そしてそれらを一つの物として利用する為に
MERGEテーブルを作成する事ができます。スピードを上げる事ができます。大きいリードオンリーのテーブルを、いくつかの基準に基づいて分割し、個々のテーブルを別々のディスク上に置く事ができます。このような場合は、
MERGEテーブルを利用した方が、大きいテーブルを利用するより早く処理ができます。より有効な検索を行う事ができます。何を探しているかが明らかであれば、いくつかのクエリを分割されたテーブルのうちの一つだけで検索し、それ以外の物に対しては
MERGEテーブルを使用します。共通のテーブル一式を利用する、別々のMERGEテーブルをいくつも持つ事もできます。より有効な検索を行う事ができます。一つの大きなテーブルを修正するよりも、
MERGEテーブルに位置づけられた個々のテーブルを修正するほうが簡単です。瞬時にいくつものテーブルを一つの物として位置づけます。
MERGEテーブルは個々のテーブルのインデックスを利用するので、それ自体のインデックスを整備する必要がありません。その結果、MERGEテーブルの集まりは、作成や最位置づけを大変 速いスピードで行うことができます。(インデックスが何も作成されていないとしても、MERGEテーブルを作成する時はインデックス定義を指定しなければいけない事を覚えておいてください。)要求に応じて作成した大きなテーブルにテーブル一式がある場合、それらの代わりに要求に応じた
MERGEテーブルを作成する必要があります。この方が、ディスクの場所を節約し、すばやく処理する事ができます。オペレーティングシステムのファイルサイズ制限を上回ります。一つ一つの
MyISAMテーブルはこの制限に制約されますが、MyISAMテーブルの集まりは制約されません。その一つのテーブルに位置づける
MERGEテーブルを定義する事によって、MyISAMテーブルに仮名や同義語を作成する事ができます。この作業を行う事によって特に顕著なインパクトは現れません。(個々の読み取りに対していくつかの間接的なコールやmemcpy()コールがあるだけです。)
MERGE
テーブルの不都合な点は次のような物です。
MERGEテーブルに対して、同一のMyISAMテーブルしか利用する事ができません。MERGEテーブルの中で、いくつものMyISAMフィーチャーを利用する事はできません。例えば、MERGEテーブル上でFULLTEXTインデックスを作成する事はできません。(もちろん、基礎となるMyISAMテーブル上にFULLTEXTインデックスを作成する事はできますが、全文検索でMERGEテーブルを検索する事はできません。もし
MERGEテーブルがテンポラリーでない場合、基礎となる全てのMyISAMテーブルもそうでなければいけません。もしMERGEテーブルがテンポラリーであれば、MyISAMテーブルはテンポラリー、テンポラリーでない物の両方が混在した物になり得ます。MERGEテーブルはより多くのファイルディスクリプタを利用します。もし、10個のクライアントが10個のテーブルに位置づけるMERGEテーブルを利用する場合、サーバーは (10 × 10) + 10 個のファイルディスクリプタを利用します。(10個のクライアントに対して10個のデータファイルディスクリプター、そして、10個のインデックスファイルディスクリプターがクライアントの間で共有されます。)キーの読み込みが遅いです。 キーを読み込む時、
MERGEストレージエンジンは、与えられたキーにどれが一番近いかを確認するために、全ての基礎となるテーブルに対して読み込みを行う必要があります。次のキーを読み込む時、 それを見つける為にMERGEストレージエンジンは、読み込みバッファを検索する必要があります。 一つのキーバッファを使い切った時に限り、ストレージエンジンは次のキーブロックを読み込む必要があります。この為にeq_ref検索のMERGEキーが遅くなりますが、ref検索ほど遅くはありません。eq_refとrefの詳細については項6.2.1. 「EXPLAINを使用して、クエリを最適化する」をご参照ください。
追加情報
MERGEストレージエンジンを専門に扱うフォーラムがあります。http://forums.mysql.com/list.php?93。
既に分かっている MERGE
テーブルの問題点は次のような物です。
MERGEテーブルを別のストレージエンジンに変える為に、ALTER TABLEテーブルを利用すると、基礎となるテーブルへの位置付けが失われます。その代わりに、基礎となるMyISAMテーブルのレコードが変化したテーブルにコピーされ、そしてそれは指定されたストレージエンジンを利用します。REPLACEは機能しません。MERGEテーブルは領域確保をサポートしません。これは、MERGEテーブルも、MERGEテーブルの基礎となるMyISAMテーブルも領域確保ができないという事です。開いている
MERGEテーブルにマップされた全てのテーブルに対して、WHERE条項、REPAIR TABLE、TRUNCATE TABLE、OPTIMIZE TABLE、またANALYZE TABLEがないDROP TABLE、ALTER TABLE、DELETEを使う事はできません。それをするとMERGEテーブルは元のテーブルを参照する事があるので、好ましくない結果をもたらす可能性があります。このような事を防ぐのに一番簡単なのは、FLUSH TABLESステートメントを事前に発行する事によって、全てのMERGEテーブルを閉じておくという方法です。MERGEストレージエンジンのテーブル位置づけはMySQLの上位レイヤーから隠れているので、MERGEテーブルによって使用されているDROP TABLEはWindowsでは機能しません。Windowsでは開いているファイルを削除する事はできないので、まずMERGEテーブルをフラッシュするか(FLUSH TABLESを使う)、テーブルをドロップする前にMERGEテーブルをドロップする必要があります。MERGEテーブルは、そのテーブル全体に対して一意性制約を保持する事ができません。INSERTを行う時、データは最初、または最後のMyISAMテーブルに入ります。(INSERT_METHODオプションの値による。)MySQLはMyISAMテーブルの中では一意の値はそのまま残る事を保障しますが、全てのテーブルのコレクションの中ではそうではありません。MySQL 5.1.15以降のバージョンでは、アクセスされた時に
MyISAMテーブルとMERGEテーブルの定義が確認されます。(例SELECTかINSERTステートメントの一部として)。そのように確認する事によって、テーブル定義と親MERGEテーブル定義がカラムの順番、タイプ、サイズ、そして関連するインデックスなどに関して一致する事を保障します。テーブル間で違いがあれば、エラーが発生し、ステートメントは失敗します。テーブルが開かれた時にこのようなチェックが行われるので、カラム変更、カラムの順番やエンジンの入れ替え等を含む定義の変更によってステートメントが失敗します。
MySQL 5.1.14 とそれ以前のバージョンにて
MERGEテーブルを修正、または作成する時、基礎となるテーブルがMyISAMテーブル内に存在し、それらが同一の構造である事を保証する為の確認は行われません。MERGEテーブルが使用される時、MySQL は全てのマップされたテーブルの行の長さが等しいかどうかを確認しますが、これは絶対間違いの無い物ではありません。異なるMyISAMテーブルからMERGEテーブルを作成すると、未知の問題に直面する可能性が高いです。同じように、
MyISAMテーブル以外からMERGEテーブルを作成したり、または基礎となるテーブルをMyISAMテーブル以外にドロップしたり変更したりすると、後でMERGEテーブルを使用する時までエラーは発生しません。基礎となる
MyISAMテーブルは、MERGEテーブルが作成される時には存在する必要がないので、全ての基礎となるテーブルが配置されるまでMERGEテーブルを使用しなければ、テーブルをどんな順番で作成しても構いません。また、MERGEテーブルが与えられた時間内に使用されない事を保障できるのであれば、基礎となるテーブルのバックアップ、リストア、変更、ドロップ、または再作成などのメンテナンスを行う事ができます。基礎となるテーブルに対して作業を行っている間に、それらを除外する為にMERGEテーブルを一時的に再定義する必要はありません。
MERGEテーブル内と、その基礎となるテーブルのインデックスの順番は同一でなければいけません。もしMERGEテーブル内で使われるテーブルにUNIQUEインデックスを追加する為にALTER TABLEを使用し、またMERGEテーブルに一意ではないインデックスを追加するためにALTER TABLEを利用するなら、基礎となるテーブルの中に既に一意ではないインデックスがあれば、テーブルのインデックス順は異なります。(これは、 重複キーの速やかな検出を促進する為にALTER TABLEがUNIQUEインデックスを一意でないインデックスの前に置くからです。)その結果、そのようなインデックスを持つテーブルに対するクエリは予想外の結果をもたらします。もし
ERROR 1017 (HY000): Can't find file: 'と同じようなエラーメッセージが出たら、それは通常いくつかのベーステーブルがMyISAMストレージエンジンを使用していない事を表します。全てのテーブルがMyISAMである事を確認してください。mm.MRG' (errno: 2)MyISAMにもあるように、MERGEテーブルにも232 (~4.295E+09)行の制限があります。その為、この制限を越える複数のMyISAMテーブルをマージする事はできません。しかし、 MySQLを--with-big-tablesオプションで作成すると、行の制限は (232)2 (1.844E+19) 行に増加します。詳しくは項2.9.2. 「典型的な configure オプション」を参照してください。MySQL 5.0.4バージョンより、全ての標準バイナリはこのオプションで作成されます。
MEMORY
ストレージエンジンはメモリ上に情報を格納するテーブルを作成します。従来、これらは
HEAP
テーブルと呼ばれていましたが、 現在
MEMORY テーブルへ名称変更されています。 ただし、
下位互換性があるため HEAP
も引き続きサポートします。
各
MEMORY テーブルは一つのディスクファイルと関連付けられています。ファイルネームはテーブルの名前で始まり、テーブル定義を格納することを示す為に拡張子 .frm
をつけます。
MEMORY テーブル作成を明確に指示したい場合は、 ENGINE
テーブルオプションを指定します。
CREATE TABLE t (i INT) ENGINE = MEMORY;
その名前からもわかるように、MEMORY
テーブルはメモリ上に格納されます。ハッシュインデックスを使用し、処理が非常に高速で、テンポラリーテーブルを作成するのに大変便利です。ただし、サーバがクラッシュすると、この MEMORY
テーブルに格納されたすべてのデータが失われます。テーブル自体は、定義がディスク上に
.frm
ファイルで格納されているので引き続き存在しますが、サーバが再起動したときにはデータは全て失われています。
ここに例として挙げるのは、MEMORY
テーブルの作成・利用・破棄の方法です。
mysql>CREATE TABLE test ENGINE=MEMORY->SELECT ip,SUM(downloads) AS down->FROM log_table GROUP BY ip;mysql>SELECT COUNT(ip),AVG(down) FROM test;mysql>DROP TABLE test;
MEMORY
テーブルには次のような特徴があります。
MEMORYテーブルは小さなブロックに割り当てられており、100% 動的ハッシュを使用しています。オーバーフローエリア、または追加の入力スペースは必要ありません。フリーリスト用の余分な領域も必要ありません。削除されたデータはリンクリストに保存され、テーブルに新たにデータを入力する際に再利用されます。MEMORYテーブルでは、ハッシュテーブルでよく見られる削除+挿入の問題も起こりません。MEMORYテーブルは、テーブルあたり最大32インデックスまで、インデックスあたり16列、インデックスの最大幅は500バイトです。The
MEMORYストレージエンジンはHASHとBTREE両方のインデックスを使って実行します。ここに記すようにUSING節 を追加することによりどちらのインデックスであるかを明確にすることが出来ます。CREATE TABLE lookup (id INT, INDEX USING HASH (id)) ENGINE = MEMORY; CREATE TABLE lookup (id INT, INDEX USING BTREE (id)) ENGINE = MEMORY;B-Treeインデックスとハッシュインデックスの一般的特徴は 項6.4.5. 「MySQLにおけるインデックスの使用」 に記載されています。
MEMORYテーブルに、一意でないキーを使用出来ます (ハッシュテーブルにはあまり見られない機能です)。MEMORYテーブル上に重複キーをもつハッシュインデックスがある場合(作成されるインデックスは同じ値を持つことが多い)、 キーの値に影響を与えるテーブルアップデートと、全ての消去は非常に処理が遅くなります。処理速度がどの程度落ちるかは、重複の度合いに比例します (或いは、インデックス濃度に反比例します。) 。BTREEインデックス を使用すれば、この問題は生じません。インデックスを張ったカラムが
NULL値を含みます。MEMORYテーブルが固定長のレコードフォーマットを使用しています。MEMORYテーブルはBLOBやTEXTカラムをサポートしません。MEMORYはAUTO_INCREMENTカラムのサポートもしています。INSERT DELAYEDのスレッドをMEMORYテーブルで使用出来ます。詳しくは項12.2.4.2. 「INSERT DELAYED構文」を参照してください。MEMORYテーブルは全てのクライアント間で共有されます(他のTEMPORARYと同様。)。MEMORYテーブルのデータはメモリ内に格納されますが、MEMORYテーブルは、クエリ実行中サーバが作成するテンポラリーテーブルとその情報を共有します。しかしながら、MEMORYテーブルの種類が異なる二つのテーブルは格納変換の対象となりませんが、一方テンポラリーテーブルについては:テンポラリーテーブルのサイズが大きくなりすぎると、サーバは自動的にテーブル形式を変換してディスクに格納します。最大サイズはシステム変数
tmp_table_sizeから求められます。MEMORYテーブルは決してディスク上のテーブルに変換されないようにします。誤った操作を行わないために、max_heap_table_sizeシステム変数をセットしてMEMORYテーブルの最大サイズを設定することが出来ます。個々のテーブルに関しては、CREATE TABLEステートメントの中でMAX_ROWSのオプションを指定することも出来ます。
サーバには、同時に動作する全ての
MEMORYテーブルを維持するための十分なメモリが必要です。MEMORYテーブルの不要になったメモリを開放するには、DELETEまたはTRUNCATE TABLEを実行するか、DROP TABLEを指定してテーブルをまとめて削除します。MySQLサーバ起動時に
MEMORYテーブルにデータを投入したい場合は、--init-fileオプションを指定します。例えば、ファイルにINSERT INTO ... SELECTまたはLOAD DATA INFILEiなどのステートメントを使用し、固定データソースからテーブルを取り込むことが出来ます。項4.2.2. 「コマンド オプション」、項12.2.5. 「LOAD DATA INFILE構文」 参照。レプリケーションを使用している場合、 シャットダウン、再起動後のマスタサーバの
MEMORYテーブルは空になっています。ところが、スレーブはこれを認識しないため、そこにある情報は古いものとなってしまいます。マスタ起動後、マスタ上のMEMORYテーブルを初めて使う際、DELETEステートメントがマスタのバイナリログに自動的に書き込まれます。このようにして、スレーブをマスタに再び一致させます。 ここで注意することは、この方法によっても、マスタ再起動からその後のテーブル使用時までのインターバル中、スレーブは依然として古いデータを保存し続けているということです。ただし、マスタ起動時MEMORYテーブルにデータを投入する際--init-fileオプションを使用することにより、このインターバルタイムはゼロになります。MEMORYテーブル上、一行に必要なメモリは以下の表現で算出できます。SUM_OVER_ALL_BTREE_KEYS(
max_length_of_key+ sizeof(char*) × 4) + SUM_OVER_ALL_HASH_KEYS(sizeof(char*) × 2) + ALIGN(length_of_row+1, sizeof(char*))ALIGN()は行の長さをcharポインタサイズのちょうど倍数にするための数式です。sizeof(char*)は32ビットマシンでは4、64ビットマシンでは8です。
追加情報
MEMORYストレージエンジンを専門に扱うフォーラムがあります。 http://forums.mysql.com/list.php?92.
EXAMPLE
ストレージエンジンはスタブで実装されており、何の機能も持ちません。このエンジンは、MySQL
ソースコードの中で新しいストレージエンジンを作成する方法を説明するための、見本の役割を果たしています。それ自体は、ソフトウェア開発者向のものです。
ソースからMySQLを構築し EXAMPLE
ストレージエンジンの機能を有効にするには、--with-example-storage-engine オプションの configure
コマンドを呼び出します。
EXAMPLE
エンジンのソースを調べるには、MySQL
ソースディストリビューションの
storage/example
ディレクトリを検索します。
EXAMPLE テーブルを作成すると、サーバーはデータベースのディレクトリ上にテーブル形式のファイルを作成します。ファイルはテーブル名から始まり
.frm
拡張子が付きます。これ以外のファイルは作成されません。このテーブルにはデータは格納されません。検索しても結果は得られません。
mysql>CREATE TABLE test (i INT) ENGINE = EXAMPLE;Query OK, 0 rows affected (0.78 sec) mysql>INSERT INTO test VALUES(1),(2),(3);ERROR 1031 (HY000):Table storage engine for 'test' doesn't ≫ have this option mysql>SELECT * FROM test;Empty set (0.31 sec)
EXAMPLE
ストレージエンジンはインデックスをサポートしません。
FEDERATED
ストレージエンジンは、レプリケーションやクラスターテクノロジを使わずに、ローカルサーバ上のリモートMySQLデータベースからデータにアクセスすることを可能にします。FEDERATED
テーブルを利用する時、ローカルサーバ上のクエリはリモート(federated)テーブル上で自動的に
実行されます。ローカルテーブル上にはデータは何も格納されません。
ソースからMySQLを構築し FEDERATED
ストレージエンジンの機能を有効にするには、--with-federated-storage-engine オプションの configure
コマンドを呼び出します。
FEDERATED
エンジンのソースを調べるには、MySQL
ソースディストリビューションの
sql ディレクトリを検索します。
MyISAMや CSV または
InnoDBなどのような標準的なストレージエンジンを利用してテーブルを作成する時、それはテーブル定義とその関連データによって構成されます。FEDERATED
テーブルを作成する時、テーブル定義は同じですが、データの物理記憶はリモートサーバ上で処理されます。
FEDERATED
テーブルは2つの要素で成り立っています。
データベースのあるリモートサーバ、(
.frmファイルに格納されている)テーブル定義や関連テーブルのテーブルによって成り立っているものであると言い換える事もできます。リモートテーブルのテーブルタイプはMyISAMやInnoDBを含むリモートmysqldサーバにサポートされている全てのタイプと言えるかもしれません。リモートサーバ上のテーブル定義とマッチするデータベースを持つ ローカルサーバ テーブル定義は
.frmファイルの中に格納されています。しかし、ローカルサーバにはデータファイルはありません。その代わりに、テーブル定義はリモートテーブルを指し示すコネクション文字列を含んでいます。
ローカルサーバ上のFEDERATED
テーブルでクエリやステートメントを実行する時、通常は情報をローカルデータファイルから挿入、アップデート、または削除する操作が、その代わりにリモートサーバに送られ、そこでデータファイルをアップデートしたり、適合する行を戻したりします。
FEDERATED
テーブルセットアップの基本的な構造は
図?13.2. 「FEDERATED テーブル構造」に示されています。
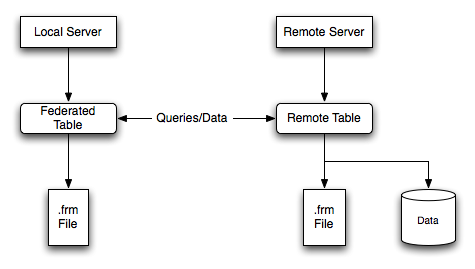
ローカルサーバ(SQLステートメントが実行される所)とリモートサーバ(データが物質的に保管される所)間での情報の流れは次のようになっています。
SQLコールが局所的に発行される
MySQL ハンドラ API (ハンドラーフォーマットのデータ)
MySQL クライアント API (SQLコールに変換されたデータ)
リモートデーベース -> MySQL クライアント API
結果があればそれをハンドラフォーマットに変換する
ハンドラ API -> 結果行、または行に影響された部分的な計算
FEDERATED
テーブルを作成するには、これらのステップに従わなければいけません。
リモートサーバ上にテーブルを作成します。または、
SHOW CREATE TABLEステートメントを利用したりして、存在するテーブルのテーブル定義のノートを作成します。ローカルサーバ上に同一のテーブル定義を使ってテーブルを作成しますが、そのときローカルテーブルをリモートテーブルにリンクさせるための接続情報を追加します。
例えば、リモートサーバ上に次のようなテーブルを作成することができます。
CREATE TABLE test_table (
id INT(20) NOT NULL AUTO_INCREMENT,
name VARCHAR(32) NOT NULL DEFAULT '',
other INT(20) NOT NULL DEFAULT '0',
PRIMARY KEY (id),
INDEX name (name),
INDEX other_key (other)
)
ENGINE=MyISAM
DEFAULT CHARSET=latin1;
リモートテーブルに連合されたローカルテーブルを作成するには、二つのオプションがあります。ローカルテーブルを作成し、CONNECTIONを利用して、リモートテーブルに接続するために使う接続文字列(サーバ名とログインパスワードを含んでいる)を指定したり、または、CREATE
SERVER
ステートメントを利用して既に作成済の接続を利用する事ができます。
注意
ローカルテーブルを作成する時、 must はリモートテーブルと同一の定義を持ちます。
最初の方法を使うには、CREATE TABLE
ステートメントのエンジンタイプの後ろに
CONNECTION
文字列を指定する必要があります。例:
CREATE TABLE federated_table (
id INT(20) NOT NULL AUTO_INCREMENT,
name VARCHAR(32) NOT NULL DEFAULT '',
other INT(20) NOT NULL DEFAULT '0',
PRIMARY KEY (id),
INDEX name (name),
INDEX other_key (other)
)
ENGINE=FEDERATED
DEFAULT CHARSET=latin1
CONNECTION='mysql://fed_user@remote_host:9306/federated/test_table';
注意
CONNECTION
はMySQLの以前のバージョンで使われた
COMMENT を置き換えます。
CONNECTION 文字列は
データを物質的に格納する為に利用されるテーブルを含む、リモートサーバに接続する為に要求される情報を含んでいます。接続文字列は、サーバ名、ログイン実績、ポート番号、そしてデータベースとテーブルの情報を指定します。
例の中では、リモートテーブルはポート9306を利用しているサーバ
remote_host
上にあります。名前とポート番号は、リモートテーブルとして利用するリモートMySQLサーバインスタンスのホスト名(またはIPアドレス)とポート番号に適合する必要があります。
接続文字列のフォーマットは次のようになります。
scheme://user_name[:password]@host_name[:port_num]/db_name/tbl_name
場所:
scheme? は認識された接続プロトコルです。この時点では、mysqlだけがscheme値としてサポートされています。user_name? 接続用のユーザ名です。このユーザはリモートサーバ上に作成されなければいけません。そして、リモートテーブル上で要求された処理(SELECT,INSERT,UPDATEetc.)を行うために適切な権限を持つ必要があります。password? (任意)usernameに対応するパスワードhost_name? リモートサーバのホスト名、またはIPアドレスport_num? (任意) リモートサーバのポート番号。デフォルトは3306です。db_name? リモートテーブルを保有するデータベースの名前。table_name? リモートテーブルの名前。ローカルテーブルとリモートテーブルの名前は一致する必要はありません。
接続文字列の例
CONNECTION='mysql://username:password@hostname:port/database/tablename' CONNECTION='mysql://username@hostname/database/tablename' CONNECTION='mysql://username:password@hostname/database/tablename'
同じサーバ上にいくつかのFEDERATEDテーブルを作成する場合や、FEDERATEDテーブルの作成プロセスをシンプルにしたい場合には、CONNECTION
文字列の時と同じように、サーバ接続パラメータを定義するために
CREATE SERVER
ステートメントを利用する事ができます。
CREATE SERVER
ステートメントのフォーマットは
CREATE SERVERserver_nameFOREIGN DATA WRAPPERwrapper_nameOPTIONS (option ...)
server_name
は新しいFEDERATEDテーブルを作成する時、接続文字列として利用されます。
例えば、CONNECTION
文字列と同一のサーバ接続を作成するには
CONNECTION='mysql://root@remote_host:9306/federated/test_table';
以下のステートメントを利用する必要があります。
CREATE SERVER fedlink FOREIGN DATA WRAPPER mysql OPTIONS (USER 'fed_user', HOST 'remote_host', PORT 9306, DATABASE 'federated');
この接続を利用した FEDERATED
テーブルを作成するには、CONNECTIONキーワードも使うのですが、CREATE
SERVERステートメントで使用した名前を指定してください。
CREATE TABLE test_table (
id INT(20) NOT NULL AUTO_INCREMENT,
name VARCHAR(32) NOT NULL DEFAULT '',
other INT(20) NOT NULL DEFAULT '0',
PRIMARY KEY (id),
INDEX name (name),
INDEX other_key (other)
)
ENGINE=MyISAM
DEFAULT CHARSET=latin1
CONNECTION='fedlink.test_table';
この例の中の接続名には、(fedlink)
接続名と、リンクされる(test_table)テーブル名が、ピリオドで区切られて含まれています。この方法で明確にテーブル名を指定しないと、代わりにローカルテーブルのテーブル名が使用されます。
CREATE SERVERについては
項12.1.11. 「CREATE SERVER 構文」を参照してください。
CREATE SERVER
ステートメントは、CONNECTION文字列と同じ引数を受け入れます。CREATE
SERVER ステートメントは
mysql.servers
テーブルの中のレコードをアップデートします。接続文字列を利用する時、CREATE
SERVERステートメントのオプションと、mysql.serversテーブルカラムなど、テーブルのパラメータ情報を見てください。次にあるのが、参照用のCONNECTION
文字列のフォーマットです。
scheme://user_name[:password]@host_name[:port_num]/db_name/tbl_name
| 解説 | CONNECTION 文字列 | CREATE SERVER オプション | mysql.servers カラム |
|---|---|---|---|
| 接続スキーム | scheme | wrapper_name | Wrapper |
| リモートユーザ | user_name | USER | Username |
| リモートパスワード | password | PASSWORD | Password |
| リモートホスト | host_name | HOST | Host |
| リモートポート | port_num | PORT | Port |
| リモートデータベース | db_name | DATABASE | Db |
FEDERATEDストレージエンジンを使用する時は、次の点に注意する必要があります。
FEDERATEDテーブルは他のスレーブに複製されることもあります。しかし、リモートサーバに接続するためには、スレーブサーバがCONNECTION(またはmysql.serversテーブルのレコード)で定義されたユーザ/パスワードの組み合わせを確実に利用できなければいけません。
次の項目は FEDERATED
ストレージエンジンがサポートする、またはしない特徴を指定します。
最初のバージョンでは、リモートサーバはMySQLサーバでなければいけませんでした。
FEDERATEDによるその他のデータベースエンジンのサポートは将来追加される可能性があります。FEDERATEDテーブルを指し示すリモートテーブルはFEDERATEDテーブルを通してそこにアクセスしようと試みる前に既に存在していなければいけません。一つの
FEDERATEDテーブルが他の物を指し示す事は可能ですが、その時ループを作成しないように気をつける必要があります。FEDERATEDテーブル上で 大量挿入(例えばINSERT INTO ... SELECT ...ステートメント上で)などを行う時は、それぞれの選択されたレコードがfederated テーブル上で個別のINSERTステートメントとして扱われるので、他のテーブルタイプで行う時と比べると動作は遅いです。トランザクションはサポートされていますが、現在は配信されたトランザクション(XA)サポートされていません。
FEDERATEDエンジンは、リモートテーブルが変えられているかどうかを知る事はできません。それは、このテーブルはデータベース以外の物には書き込まれる事がない、データファイルのように機能しなければいけないからです。ローカルテーブル内のデータのインテグリティは、リモートデータベースに何か変更があると破壊される事があります。FEDERATEDストレージエンジンは、SELECT、INSERT、UPDATE、DELETE、TRUNCATE、そしてインデックスをサポートします。ALTER TABLEや、DROP TABLE以外のデータ定義言語 ステートメントはサポートしません。現在のインプリメンテーションは、用意されたステートメントを利用しません。CONNECTION文字列を利用する時、パスワードに '@'を用いることはできません。 この制限は、サーバ接続を作成する時にCREATE SERVERを利用すれば避ける事ができます。INSERT_IDとTIMESTAMPオプションは、データ提供者に対して用意されている物ではありません。FEDERATEDテーブルに対して発行されたDROP TABLEステートメントは、ローカルテーブルは除去しますが、リモートテーブルは除去しません。インプリメンテーションは、
SELECT、INSERT、UPDATE、そしてDELETEを利用しますが、HANDLERは利用しません。FEDERATEDテーブルはクエリキャッシュとは機能しません。ユーザー定義領域確保は
FEDERATEDテーブルの為にはサポートされていません。MySQL 5.1.15からは、そのような テーブルを作成する事は不可能になりました。
これらの制限のうちのいくつかは、FEDERATED
ハンドラの今後のバージョンで撤廃されるでしょう。
次の追加リソースをFEDERATED
ストレージエンジンに利用する事ができます。
FEDERATEDストレージエンジンを専門に扱うフォーラムがあります。http://forums.mysql.com/list.php?105
ARCHIVE
ストレージエンジンは、小さい容量の中に大量のデータをインデックスなしで記憶しておく為に使われます。
ARCHIVE
ストレージエンジンはMySQLの2極分布に含まれています。ソースからMySQLを構築し
このストレージエンジンの機能を有効にするには、--with-archive-storage-engine オプションの configure
コマンドを呼び出します。
ARCHIVE
エンジンのソースを調べるには、MySQL
ソースディストリビューションの
storage/archive
ディレクトリを検索します。
このステートメントを使って ARCHIVE
ストレージエンジンが有効かどうかを調べる事が出来ます。
mysql> SHOW VARIABLES LIKE 'have_archive';
ARCHIVE テーブルを作成すると、サーバはデータベースのディレクトリ上にテーブル形式のファイルを作成します。ファイルはテーブル名から始まり
.frm
拡張子が付きます。ストレージエンジンはその他のファイルを作成し、それら全てはテーブル名で始まる名前を持ちます。データとメタデータファイルはそれぞれ
.ARZ と .ARM
という拡張子を持ちます。最適化作業の最中に
.ARN
ファイルが現れる事があります。
ARCHIVE エンジンは INSERT
と SELECT
をサポートしますが、DELETE と
REPLACE そして UPDATE
はサポートしません。また、基本的に ORDER
BY オペレーション、 BLOB
カラム、そして空間データタイプ (項16.4.1. 「MySQL Spatial Data Types」を参照) 以外の全てをサポートします。ARCHIVE
エンジンは低レベルロッキングを使用します。
MySQL 5.1.6にもあるように ARCHIVE
ンジンは AUTO_INCREMENT
カラム属性をサポートします。AUTO_INCREMENT
カラムは固有、または固有で無いインデックスの両方を持つ事が出来ます。それ以外のコラムにインデックスを作成しようとしてもエラーが発生します。ARCHIVE
エンジンは、 CREATE TABLE や
ALTER
TABLE ステートメントの中の AUTO_INCREMENT
テーブルオプションを新しいテーブルの初期シーケンス値を指示する為や、既に存在するテーブルのシーケンス値を再設定する時に、それぞれをサポートします。
MySQL 5.1.6にあるように、ARCHIVE
エンジンは、BLOB
カラムが要求されていない時や読み取り中にスキャンがパスした時はそれらを無視します。以前は次の二つのステートメントは同等のコストでしたが、5.1.6では2つ目が1つ目よりも大変効率的になりました。
SELECT a, b, blob_col FROM archive_table; SELECT a, b FROM archive_table;
保存:
挿入されると行は圧縮されます。ARCHIVE
エンジンは zlib
ロスレスデータ圧縮を使用しています (http://www.zlib.net/を参照)。OPTIMIZE
TABLE
テーブルを分析し、それをもっと小さいフォーマットにまとめる為に
(OPTIMIZE
TABLE を利用する理由に関しては、このセクションの後半を参照して下さい。)
このエンジンは CHECK
TABLEもサポートしています。次のような何種類かの挿入方法が使用されています。
INSERTステートメントが行を圧縮バッファに押し入れ、そのバッファは必要に応じてフラッシュします。バッファへの挿入はロックによって保護されます。SELECTは、INSERT DELAYED(必要に応じてフラッシュする) だけが挿入された場合を除いて、強制的にフラッシュを発生させます。詳しくは項12.2.4.2. 「INSERT DELAYED構文」を参照してください。大量挿入は、他の挿入が同時に行われなければ、完了後にだけ見えるようになります。
SELECTは、ロード中に通常挿入が行われない限り、大量挿入をフラッシュする事はありません。
取り出し:取り出しの際、要求によって行が解凍されます。行キャッシュはありません。SELECT
操作によって完全なテーブルスキャンを実行する事が出来ます。SELECT
操作は、現在いくつの行が有効かを見つけその行数を読み取ります。SELECT
操作は一貫した読み取りとして実行されます。大量挿入または遅延挿入が使用された場合以外は、挿入の最中の多くの
SELECT
ステートメントが圧縮の質を低下させる事があると覚えておいて下さい。圧縮の質を高めるには、
OPTIMIZE TABLE か REPAIR
TABLEを使う事が出来ます。SHOW TABLE
STATUS によって報告される
ARCHIVE
テーブルの行数はいつも正確です。項12.5.2.5. 「OPTIMIZE TABLE 構文」、項12.5.2.6. 「REPAIR TABLE 構文」、項12.5.4.27. 「SHOW TABLE STATUS 構文」を参照して下さい。
追加情報
ARCHIVEストレージエンジンを専門に扱うフォーラムがあります。 http://forums.mysql.com/list.php?112.
CSV
ストレージエンジンはコンマ区切りの値を使ったフォーマットでデータをテキストファイルに保存します。
MySQLを作成する時、このストレージエンジンを使用するには、
configure する為に
--with-csv-storage-engineオプションを使います。
ソースからMySQLを構築し CSV
ストレージエンジンの機能を有効にするには、--with-csv-storage-engine オプションの configure
コマンドを呼び出します。
CSV
エンジンのソースを調べるには、MySQL
ソースディストリビューションの
storage/csv
ディレクトリを検索します。
CSV テーブルを作成すると、サーバはデータベースのディレクトリ上にテーブル形式のファイルを作成します。ファイルはテーブル名から始まり
.frm
拡張子が付きます。このストレージエンジンはデータファイルも作成します。その名前はテーブル名で始まり
.CSV
という拡張子を持ちます。このデータファイルはシンプルなテキストファイルです。データをテーブルに保存する時、ストレージエンジンはコンマで区切られた値のフォーマットでそのデータをデータファイルに保存します。
mysql>CREATE TABLE test(i INT, c CHAR(10)) ENGINE = CSV;Query OK, 0 rows affected (0.12 sec) mysql>INSERT INTO test VALUES(1,'record one'),(2,'record two');Query OK, 2 rows affected (0.00 sec) Records: 2 Duplicates: 0 Warnings: 0 mysql>SELECT * FROM test;+------+------------+ | i | c | +------+------------+ | 1 | record one | | 2 | record two | +------+------------+ 2 rows in set (0.00 sec)
MySQL 5.1.9から、
CSVテーブルを作成するとテーブルの状態とそのテーブル内の行数を記憶する、対応メタファイルも同時に作成されるようになりました。このファイルの名前は
CSMという拡張子のついたテーブル名と同じです。
前回のステートメント実行時に作成されたデータベースディレクトリの中の
test.CSV
ファイルを分析すると、その中身はこのようになっているでしょう。
"1","record one" "2","record two"
このフォーマットはマイクロソフトエクセルやスターオフィスなどのような表計算アプリケーションによって読み取る事も、書き込む事も可能です。
バージョン5.1.9で紹介する機能性
CSVストレージエンジンは、損傷したCSVテーブルを検証し、可能であればそれを修正する
CHECK コマンドと REPAIR
コマンドをサポートします。
CHECK
コマンドを実行する時には、正しいフィールド区切り、エスケープフィールド(一致した引用符や欠落した引用符)、テーブル定義や対応CSVメタファイルとの比較フィールド数などを探す事によって、そのCSVファイルの正当性チェックが行われます。最初に発見された不正な行がエラーを報告します。正当なテーブルをチェックする事によって、下記のようなアウトプットが作成されます。
mysql> check table csvtest;
+--------------+-------+----------+----------+
| Table | Op | Msg_type | Msg_text |
+--------------+-------+----------+----------+
| test.csvtest | check | status | OK |
+--------------+-------+----------+----------+
1 row in set (0.00 sec)破損したテーブルを抑制するとフォルトが戻ります。
mysql> check table csvtest;
+--------------+-------+----------+----------+
| Table | Op | Msg_type | Msg_text |
+--------------+-------+----------+----------+
| test.csvtest | check | error | Corrupt |
+--------------+-------+----------+----------+
1 row in set (0.01 sec)
もし抑制に失敗するとそのテーブルにはクラッシュ(破損)の印が付きます。一度クラッシュの印がつくと、次に
CHECK を実行した時や
SELECT
命令を実行した時に、そのテーブルは自動的に修正されます。破損状態や新しい状態はCHECKを実行した時に表示されます。
mysql> check table csvtest;
+--------------+-------+----------+----------------------------+
| Table | Op | Msg_type | Msg_text |
+--------------+-------+----------+----------------------------+
| test.csvtest | check | warning | Table is marked as crashed |
| test.csvtest | check | status | OK |
+--------------+-------+----------+----------------------------+
2 rows in set (0.08 sec)
テーブルを修正するには REPAIR
を使う事が出来ます。
この機能は存在するCSVデータから可能な限りの有効な行をコピーし、存在するCSVファイルと復元された行を置き換えます。破損データを超えた行は全て失われます。
mysql> repair table csvtest;
+--------------+--------+----------+----------+
| Table | Op | Msg_type | Msg_text |
+--------------+--------+----------+----------+
| test.csvtest | repair | status | OK |
+--------------+--------+----------+----------+
1 row in set (0.02 sec)警告
修正の最中は、CSVファイルから最初のダメージを受けた行までだけが、新しいテーブルにコピーされるという事を覚えておいて下さい。それ以外の行は、有効であっても全て除去されます。
重要CSV
ストレージエンジンはインデックスをサポートしません。
CSV
ストレージエンジンを使ったテーブルの領域確保はサポートされません。MySQL
5.1.12からは、分割されたCSV
テーブルを作成する事は不可能になりました。(Bug#19307を参照して下さい。)
BLACKHOLE ストレージエンジンは
データを受け入れますがそれを格納せずに捨ててしまう「black
hole」として機能します。検索しても結果は得られません。
mysql>CREATE TABLE test(i INT, c CHAR(10)) ENGINE = BLACKHOLE;Query OK, 0 rows affected (0.03 sec) mysql>INSERT INTO test VALUES(1,'record one'),(2,'record two');Query OK, 2 rows affected (0.00 sec) Records: 2 Duplicates: 0 Warnings: 0 mysql>SELECT * FROM test;Empty set (0.00 sec)
ソースからMySQLを構築し BLACKHOLE
ストレージエンジンの機能を有効にするには、--with-blackhole-storage-engine オプションの configure
コマンドを呼び出します。
BLACKHOLE
エンジンのソースを調べるには、MySQL
ソースディストリビューションの
sql ディレクトリを検索します。
BLACKHOLE テーブルを作成すると、サーバーはデータベースのディレクトリ上にテーブル形式のファイルを作成します。ファイルはテーブル名から始まり
.frm
拡張子が付きます。テーブルに関連する他のファイルはありません。
BLACKHOLE
ストレージエンジンは全てのインデックスをサポートします。それは、インデックスデクラレーションをテーブル定義に含む事ができるという事を意味します。
このステートメントを使って BLACKHOLE
ストレージエンジンが有効かどうかを調べる事が出来ます。
mysql> SHOW VARIABLES LIKE 'have_blackhole_engine';
BLACKHOLE
テーブルへ挿入してもデータは格納されませんが、 バイナリログが有効な場合、SQLステートメントはログされます。(そしてスレーブサーバーに複製されます。)これはリピータやフィルタメカニズムに有用です。例えば、アプリケーションがスレーブサイドフィルタルールを要求したとします。しかし、スレーブに全てのバイナリログデータを転送すると、すぐにトラフィックが混み合ってしまいます。そのような場合は、次に描かれているようにマスタホスト上に、デフォルトストレージエンジンがBLACKHOLEである「dummy」スレーブプロセスをセットアップする事が可能です。
マスタはそれ自体のバイナリログに書き込みを行います。「dummy」
mysqldプロセスは、希望のreplicate-do-*
と replicate-ignore-*
ルールの組み合わせを適応させスレーブとして機能し、それ自体の新しくフィルタされたバイナリログを書きます。(詳しくは項5.1.3. 「レプリケーションのオプションと変数」をご確認ください。)このフィルタされたログはスレーブに提供されます。
ダミープロセスはデータの保存は行いませんので、レプリケーションマスタホストにmysqld プロセスを追加で実行させると、プロセスオーバーヘッドを被る事があります。このタイプのセットアップは追加のレプリケーションスレーブを使って繰り返す事ができます。
BLACKHOLEテーブルのINSERT
トリガは予想通りに機能します。しかし、BLACKHOLE
テーブルはデータの格納ができないので
UPDATE と DELETE
トリガは有効ではありません。行がないので、トリガ定義中の
FOR ANY ROW 節は適用しません。
その他のBLACKHOLE
ストレージエンジンの利用方法は次のようなものです。
ダンプファイル構文の検証
バイナリログの有無にかかわらず
BLACKHOLEを利用して性能を比較する事によって、バイナリログからのオーバーヘッド計算が可能になりました。BLACKHOLEは基本的に 「no-op」 ストレージエンジンなので、ストレージエンジン自体には関係ない性能障害を見つけることができます。
MySQL 5.1.4にあるように、
実行されたトランザクションはバイナリログに書き込まれるが、ロールバックトランザクションは書き込まれない、という意味ではBLACKHOLE
エンジンはトランザクション認識型です。